Message boards : News : ATM
| Author | Message |
|---|---|
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Hello GPUGRID! | |
| ID: 60002 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
I’m brand new to GPUGRID so apologies in advance if I make some mistakes. I’m looking forward to learn from you all and discuss about this app :) | |
| ID: 60003 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Welcome! | |
| ID: 60005 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Thanks for creating an official topic on these types of tasks. | |
| ID: 60006 | Rating: 0 | rate:
| |
|
Greger Send message Joined: 6 Jan 15 Posts: 74 Credit: 18,006,699,749 RAC: 57,363,878 Level Scientific publications | |
|
Welcome and thanks for info Quico <nbytes>729766132.000000</nbytes> <max_nbytes>10000000000.000000</max_nbytes> https://ibb.co/4pYBfNS parsing upload result response <data_server_reply> <status>0</status> <file_size>0</file_size error code -224 (permanent HTTP error) https://ibb.co/T40gFR9 I will do test new test on new units but would probably face same issue if server have not changed. https://boinc.berkeley.edu/trac/wiki/JobTemplates | |
| ID: 60007 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
File size in past history that max allowed have been 700mb Greger, are you sure it was 700mb? From what I remember, it was 500mb | |
| ID: 60009 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I have one which is looking a bit poorly. It's 'running' of host 132158l (Linux Mint 21.1, GTX 1660 super, 64 GB RAM), but it's only showing 3% progress after 18 hours. | |
| ID: 60011 | Rating: 0 | rate:
| |
|
Dirk Broer Send message Joined: 4 Oct 09 Posts: 2 Credit: 145,384,519 RAC: 938,701 Level Scientific publications | |
|
I am trying to upload one, but can't get it to do the transfer: | |
| ID: 60012 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I think mine is a failure. Nothing has been written to stderr.txt since 14:22:59 UTC yesterday, and the final entries are: + echo 'Run AToM' + CONFIG_FILE=Tyk2_new_2-ejm_49-ejm_50_asyncre.cntl + python bin/rbfe_explicit_sync.py Tyk2_new_2-ejm_49-ejm_50_asyncre.cntl Warning: importing 'simtk.openmm' is deprecated. Import 'openmm' instead. I'm aborting it. NB a previous user also failed with a task from the same workunit: 27418556 | |
| ID: 60013 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Thanks everyone for the replies! Welcome and thanks for info Quico Thanks for this, I'll keep that in mind. From the succesful run the size file is 498M so it should be on the limit there to what @Erich56 says. But that's useful information for when I run bigger systems. I think mine is a failure. Nothing has been written to stderr.txt since 14:22:59 UTC yesterday, and the final entries are: Hmmm, that's weird. It shouldn't softlock in that step. Although this warning pops up it should keep running without issues. I'll ask around | |
| ID: 60022 | Rating: 0 | rate:
| |
|
gemini8 Send message Joined: 3 Jul 16 Posts: 31 Credit: 1,571,387,676 RAC: 5,139,196 Level Scientific publications | |
|
This task didn't want to upload, but neither would GPUGrid update when I aborted the upload. | |
| ID: 60029 | Rating: 0 | rate:
| |
|
STE\/E Send message Joined: 18 Sep 08 Posts: 368 Credit: 452,767,298 RAC: 200,417 Level Scientific publications | |
|
I just aborted 1 ATM Wu https://www.gpugrid.net/result.php?resultid=33338739 that had been running for over 7 Days, it sat at 75% done the whole time. Got another one & it immediately jumped to 75% done. Probably just abort it & deselect any new ATM Wu's ... | |
| ID: 60035 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Some still running, many failing. | |
| ID: 60036 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Three successive errors on host 132158 | |
| ID: 60037 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
I let some computers run off all other WUs so they were just running 2 ATM WUs. It appears they do only use one CPU each but that may just be a consequence of specifying a single CPU in the client_state.xml file. Might your ATM project benefit from using multiple CPUs? <app_version> nvidia-smi reports ATM 1.13 WUs are using 550 to 568 MB of VRAM so call it 0.6 GB VRAM. BOINCtasks reports all WUs are using less than 1.2 GB RAM. That means that my computers could easily run up to 20 ATM WUs simultaneourly. Sadly GPUGRID does not allow us to control the number of WUs we DL like LHC or WCG do. So we're stuck with 2 set by the ACEMD project. I never run more than a single PYTHON WU on a computer so I get two and abort one and then have to uncheck PYTHON in my GPUGRID Preferences just in case ACEMD or ATM WUs materialize. I wonder how many years it's been since GG has improved the UI to make it more user-friendly? When one clicks their Preferences they still get 2 Warnings and 2 Strict Standards that have never been fixed.<app_name>ATM</app_name> <version_num>113</version_num> <platform>x86_64-pc-linux-gnu</platform> <avg_ncpus>1.000000</avg_ncpus> <flops>46211986880283.171875</flops> <plan_class>cuda1121</plan_class> <api_version>7.7.0</api_version> Please add a link to your applications: https://www.gpugrid.net/apps.php ____________  | |
| ID: 60038 | Rating: 0 | rate:
| |
|
kksplace Send message Joined: 4 Mar 18 Posts: 53 Credit: 1,816,356,749 RAC: 6,127,466 Level Scientific publications | |
|
Is there a way to tell if an ATM WU is progressing? I have had only one succeed so far over the last several weeks. However, all of the failures so far were one of two types: either a failure to upload (and the download aborted by me) or a simple "Error while computing", which happened very quickly. | |
| ID: 60039 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
let me explain something about the 75% since it seems many don't understand what's happening here. the 75% is in no way an indication of how much the task has progressed. it is totally a function of how BOINC acts with the wrapper when the tasks are setup in the way that they are. | |
| ID: 60041 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I have one that's running (?) much the same. I think I've found a way to confirm it's still alive. 2023-03-08 21:55:05 - INFO - sync_re - Started: sample 107, replica 12 2023-03-08 21:55:17 - INFO - sync_re - Finished: sample 107, replica 12 (duration: 12.440164870815352 s) which seems to suggest that all is well. Perhaps Quico could let us know how many samples to expect in the current batch? | |
| ID: 60042 | Rating: 0 | rate:
| |
|
kksplace Send message Joined: 4 Mar 18 Posts: 53 Credit: 1,816,356,749 RAC: 6,127,466 Level Scientific publications | |
|
Thanks for the idea. Sure enough, that file is showing activity (On sample 324, replica 3 for me.) OK. Just going to sit and wait. | |
| ID: 60043 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
I have one that's running (?) much the same. I think I've found a way to confirm it's still alive. Thanks for this input (and everyone's). At least in the runs I sent recently we are expecting 341 samples. I've seen that there were many crashes in the last batch of jobs I sent. I'll check if there were some issues on my end or it's just that the systems decided to blow up. | |
| ID: 60045 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
At least in the runs I sent recently we are expecting 341 samples. Thanks, that's helpful. I've reached sample 266, so I'll be able to predict when it's likely to finish. But I think you need to reconsider some design decisions. The current task properties (from BOINC Manager) are:  This task will take over 24 hours to run on my GTX 1660 Ti - that's long, even by GPUGrid standards. BOINC doesn't think it's checkpointed since the beginning, even though checkpoints are listed at the end of each sample in the job.log BOINC Manager shows that the fraction done is 75.000% - and has displayed that figure, unchanging, since a few minutes into the run. I'm not seeing any sign of an output file (or I haven't found it yet!), although it's specified in the <result> XML: <file_ref> <file_name>T_QUICO_Tyk2_new_2_ejm_47_ejm_55_4-QUICO_TEST_ATM-0-1-RND8906_2_0</file_name> <open_name>output.tar.bz2</open_name> <copy_file/> </file_ref> More when it finishes. | |
| ID: 60046 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
At least in the runs I sent recently we are expecting 341 samples. That's good to know, thanks. Next time I'll prepare them so they run for shorter amounts of time and finish over next submissions. Is there an aprox time you suggest per task? I'm not seeing any sign of an output file (or I haven't found it yet!), although it's specified in the <result> XML: Can you see a cntxt_0 folder or several r0-r21 folders? These should be some of the outputs that the run generates, and also the ones I'm getting from the succesful runs. | |
| ID: 60047 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Can you see a cntxt_0 folder or several r0-r21 folders? These should be some of the outputs that the run generates, and also the ones I'm getting from the succesful runs. Yes, I have all of those, and they're filling up nicely. I want to catch the final upload archive, and check it for size. | |
| ID: 60048 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Can you see a cntxt_0 folder or several r0-r21 folders? These should be some of the outputs that the run generates, and also the ones I'm getting from the succesful runs. Ah I see, from what I've seen the final upload archive has been around 500MB for these runs. Taking into accont what was mentioned filesize-wise in the beginning of the thread I'll tweak some paramaters in order to avoid heavier files | |
| ID: 60049 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
you should also add weights to the <tasks> element in the jobs.xml file that's being used as well as adding some kind of progress reporting for the main script. jumping to 75% at the start and staying there for 12-24hrs until it jumps to 100% at the end is counterintuitive for most users and causes confusion about if the task is doing anything or not. | |
| ID: 60050 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
Next time I'll prepare them so they run for shorter amounts of time and finish over next submissions. Is there an aprox time you suggest per task? The sweet spot would be 0.5 to 4 hours. Above 8 hours is starting to drag. Some climate projects take over a week to run. It really depends on your needs, we're here to serve :-) It seems a quicker turn around time while you're tweaking your project would be to your benefit. It seems it would help you if you created your own BOINC account and ran your WUs the same way we do. Get in the trenches with us and see what we see. | |
| ID: 60051 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Well, here it is: | |
| ID: 60052 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Next time I'll prepare them so they run for shorter amounts of time and finish over next submissions. Is there an aprox time you suggest per task? Once the Windows version is live my personal set-up will join the cause and will have more feedback :) Well, here it is: Thanks, for the insight. I'll make it save frames less frequently in order to avoid bigger filesizes. | |
| ID: 60053 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
nothing but errors from the current ATM batch. run.sh is missing or misnamed/misreferenced. | |
| ID: 60068 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
I vaguely recall GG had a rule something like a computer can only DL 200 WUs a day. If it's still in place it would be absurd since the overriding rule is that a computer can only hold 2 WUs at a time. | |
| ID: 60069 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Today's tasks are running OK - the run.sh script problem has been cured. | |
| ID: 60074 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i wouldnt say "cured". but newer tasks seem to be fine. I'm still getting a good number of resends with the same problem. i guess they'll make their way through the meat grinder before defaulting out. | |
| ID: 60075 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
My point was: if you get one of these, let it run - it may be going to produce useful science. If it's one of the faulty ones, you waste about 20 seconds, and move on. | |
| ID: 60076 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Quico/GDF, GPU utilization is low so I'd like to test running 3 and 4 ATM WUs simultaneously. | |
| ID: 60084 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Sorry about the run.sh missing issue of the past few days. It slipped through me. Also they were a few re-send tests that also crashed, but it should be fixed now. | |
| ID: 60085 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Quico/GDF, GPU utilization is low so I'd like to test running 3 and 4 ATM WUs simultaneously. How low is it? It really shouldn't be the case at least taking into account the tests we performed internally. | |
| ID: 60086 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
My host 508381 (GTX 1660 Ti) has finished a couple overnight, in about 9 hours. The last one finished just as I was reading your message, and I saw the upload size - 114 MB. Another failed with 'Energy is NaN', but that's another question. | |
| ID: 60087 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
My observations show the GPU switching from periods of high utilization (~96-98%) to periods of idle (0%). About every minute or two. | |
| ID: 60091 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
Quico/GDF, GPU utilization is low so I'd like to test running 3 and 4 ATM WUs simultaneously.How low is it? It really shouldn't be the case at least taking into account the tests we performed internally. GPUgrid is set to only DL 2 WUs per computer. It used to be higher but since ACEMD WUs take around 12ish hours and have approxiamtely 50% GPU utilization a normal BOINC client couldn't really make efficient use of more than 2. The history of setting the limit may have had something to do with DDOS attacks and throttling server access as a defense. But Python WUs with a very low GPU utilization and ATM with about 25% utilization could run more. I believe it's possible for the work server to designate how many WUs of a given kind based on the client's hardware. Some use a custom BOINC client that tricks the server into thinking their computer is more than one computer. I suspect 1080s & 2080s could run 3 and 3080s could run 4 ATM WUs. Be nice to give it a try. Checkpointing should be high on your To-Do List followed closely by progress reporting. File size is not an issue on the client side since you DL files over a GB. But increasing the limit on your server side would make that problem vanish. Run times have shortened and run fine, maybe a little shorter would be nice but not a priority. | |
| ID: 60093 | Rating: 0 | rate:
| |
 Stephen Uitti Stephen UittiSend message Joined: 17 Mar 14 Posts: 4 Credit: 77,427,636 RAC: 0 Level Scientific publications | |
|
I noticed Free energy calculations of protein ligand binding in WUProp. For example, today's time is 0.03 hours. I checked, and i've 68 of these with a total of minimal time. So i checked, and they all get "Error while computing". I looked at a recent work unit, 27429650 T_CDK2_new_2_edit_1oiu_26_T2_2A_1-QUICO_TEST_ATM-0-1-RND4575_0 | |
| ID: 60094 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
GPUgrid is set to only DL 2 WUs per computer. it's actually 2 per GPU, for up to 8 GPUs. 16 per computer/host. ACEMD WUs take around 12ish hours and have approxiamtely 50% GPU utilization acemd3 has always used nearly 100% utilization with a single task on every GPU I've ever run. if you're only seeing 50%, sounds like you're hitting some other kind of bottleneck preventing the GPU from working to its full potential. ____________  | |
| ID: 60095 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
I just started using nvitop for Linux and it gives a very different image of GPU utilization while running ATM: https://github.com/XuehaiPan/nvitop | |
| ID: 60096 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i would probably give more trust to nvidia's own tools. watch -n 1 nvidia-smi or watch -n 1 nvidia-smi --query-gpu=temperature.gpu,name,pci.bus_id,utilization.gpu,utilization.memory,clocks.current.sm,clocks.current.memory,power.draw,memory.used,pcie.link.gen.current,pcie.link.width.current --format=csv but you said "acemd3" uses 50%. not ATM. overall I'd agree that ATM is closer to 50% effective or a little higher. it cycles between like 90 seconds @95+% and 30 seconds @0% and back and forth for the majority of the run. ____________ | |
| ID: 60097 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
I'm running Linux Mint 19 (a bit out of date)I just retired my last Linux Mint 19 computer yesterday and it had been running ATM, ACEMD & Python WUs on a 2080 Ti (12/7.5) fine. BTW, I tried the LM 21.1 upgrade from LM 20.3 and can't do things like open BOINC folder as admin. I can't see any advantage to 21.1 so I'm going to do a fresh install and revert back to 20.3. My machine has a gtx-950, so cuda tasks are OK.Is there a minimum requirement for CUDA and Compute Capability for ATM WUs? https://www.techpowerup.com/gpu-specs/geforce-gtx-950.c2747 says CUDA 5.2 and https://developer.nvidia.com/cuda-gpus says 5.2. | |
| ID: 60098 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Is there a minimum requirement for CUDA and Compute Capability for ATM WUs? very likely the min CC is 5.0 (Maxwell) since Kepler cards seem to be erroring with the message that the card is too old. all cuda 11.x apps are supported by CUDA 11.1+ drivers. with CUDA 11.1, Nvidia introduced forward compatibility of minor versions. so as long as you have 450+ drivers you should be able to run any CUDA app up to 11.8. CUDA 12+ will require moving to CUDA 12+ compatible drivers. ____________ | |
| ID: 60099 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
I'm sure you're right, it's been years since I put more than on GPU on a computer.GPUgrid is set to only DL 2 WUs per computer. ACEMD WUs take around 12ish hours and have approxiamtely 50% GPU utilizationacemd3 has always used nearly 100% utilization with a single task on every GPU I've ever run. if you're only seeing 50%, sounds like you're hitting some other kind of bottleneck preventing the GPU from working to its full potential.[/quote]Let me rephrase that since it's been a long time since there was a steady flow of ACEMD. I always run 2 ACEMD WUs per GPU with no other GPU projects running. I can't remember what ACEMD utilization was but I don't recall that they slowed down much by running 2 WUs together. | |
| ID: 60100 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
maybe not much slower, but also not faster. | |
| ID: 60101 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
i would probably give more trust to nvidia's own tools. nvitop does that but graphs it. | |
| ID: 60102 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
maybe not much slower, but also not faster. But it has the advantage that compared to running a single ACEMD WU and letting the second GG sit idle waiting until it finishes and not getting the quick turnaround bonus feels like getting robbed :-) But who's counting? | |
| ID: 60103 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
until your 12h task turns into two 25hr tasks running two and you get robbed anyway. robbed of the bonus for two tasks instead of just one. | |
| ID: 60104 | Rating: 0 | rate:
| |
|
Keith Myers  Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Picked up another ATM task but not holding much hope that it will run correctly based on the previous wingmen output files. Looks like the configuration is not correct again. | |
| ID: 60105 | Rating: 0 | rate:
| |
|
zombie67 [MM]  Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
|
Does the ATM app work with RTX 4000 series? | |
| ID: 60106 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Does the ATM app work with RTX 4000 series? Maybe. The Python app does, and the ATM is a similar kind of setup. You’ll have to try it and see. Not sure how much progress the project has made for Windows though. ____________ | |
| ID: 60107 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
I'm running Linux Mint 19 (a bit out of date)I just retired my last Linux Mint 19 computer yesterday and it had been running ATM, ACEMD & Python WUs on a 2080 Ti (12/7.5) fine. BTW, I tried the LM 21.1 upgrade from LM 20.3 and can't do things like open BOINC folder as admin. I can't see any advantage to 21.1 so I'm going to do a fresh install and revert back to 20.3. Glad to know someone else also has the same problem with Mint 21.1. I will shift to some other flavour. | |
| ID: 60108 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Got my first ATM Beta. Completed and validated. | |
| ID: 60111 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
My observations show the GPU switching from periods of high utilization (~96-98%) to periods of idle (0%). About every minute or two. That sounds how ATM is intended to work for now. The idle GPU periods correspond to writing coordinates. Happy to know that size of the jobs are good! Picked up another ATM task but not holding much hope that it will run correctly based on the previous wingmen output files. Looks like the configuration is not correct again. I have seen your errors but I'm not sure why it's happening since I got several jobs running smoothly right now. I'll ask around. The new tag is a legacy part on my end about receptor naming. | |
| ID: 60120 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Another heads-up, it seems that the Windows app will available soon! That way we'll be able to look into the progress reporting issue. | |
| ID: 60121 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
...it seems that the Windows app will available soon! that's good news - I'm looking foward to receiving ATM tasks :-) | |
| ID: 60123 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
|
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? | |
| ID: 60126 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? As far as I know, we are doing the final tests. I'll let you know once it's fully ready and I have the green light to send jobs through there. | |
| ID: 60128 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? do you have allow beta/test applications checked? ____________ | |
| ID: 60129 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? Yep. Are you saying that you have received windows tasks for ATM? ____________ Reno, NV Team: SETI.USA | |
| ID: 60130 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? no I don't run windows. i was just asking if you had the beta box selected because that's necessary. but looking at the server, some people did get them. someone else earlier in this thread reported that they got and processed one also. very few went out, so unless your system asked when they were available, it would be easy to miss. you can setup a script to ask for them regularly, BOINC will stop asking after so many requests with no tasks sent. ____________ | |
| ID: 60132 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? I've yet to get a Windoze ATMbeta. They've been available for a while this morning and still nothing. That GPU just sits with bated breath. What's the trick? | |
| ID: 60134 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
I see that there is a windows app for ATM. But I have never received an app on any of my win machines, even with an updater. And yes, I have all the right project preferences set (everything checked). So, has anyone received an ATM task on a windows machine? Yep. As I said, I have an updater script running as well. ____________ Reno, NV Team: SETI.USA | |
| ID: 60135 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
KAMasud got one on his Windows system. maybe he can share his settings. | |
| ID: 60136 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Quico, Do you have some cryptic requirements specified for your Win ATMbeta WUs? | |
| ID: 60137 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
KAMasud got one on his Windows system. maybe he can share his settings. ____________________ Yes, I did get an ATM task. Completed and validated with success. No, I do not have any special settings. The only thing I do is not run any other project with GPU Grid. I have a feeling that they interfere with each other. How? GPU Grid is all over my cores and threads. Lacks discipline. My take on the subject. Admin, sorry. Even though resources are wasted, I am not after the credits. | |
| ID: 60138 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
I think it's just a matter of very few tests being submitted right now. Once I have the green light from Raimondas I'll start sending jobs through the windows app as well. | |
| ID: 60139 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Still no checkpoints. Hopefully this is top of your priority list. | |
| ID: 60140 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Done! Thanks for it. | |
| ID: 60141 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
|
There ate two different ATM apps on the server stats page, and also on the apps.php page. But in project preferences, there is only one ATM app listed. We need a way to select both/either in our project preferences. | |
| ID: 60142 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Let it be. It is more fun this way. Never know what you will get next and adjust. | |
| ID: 60143 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
My new WU behaves differently but I don't think checkpointing is working. It reported the first checkpoint after a minute and after an hour has yet to report a second one. Progress is stuck at 0.2 but time remaining has decreased from 1222 days to 22 days. | |
| ID: 60144 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
|
I have started to get these ATM tasks on my windoze hosts. (unknown error) - exit code 195 (0xc3)</message> A script error? | |
| ID: 60145 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
I have started to get these ATM tasks on my windoze hosts. Hmmm I did send those this morning. Probably they entered the queue once my windows app was live and was looking for the run.bat. If that's the case expect many crashes incoming :_( The tests I'm monitoring seem to be still running so there's still hope | |
| ID: 60146 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
|
FWIW, this morning my windows machines started getting ATM tasks. Most of these tasks are erroring out. For these tasks, they have been issued many times over too many and failed every time. Looks like a problem with the tasks and not the clients running them. They will eventually work their way out of the system. But a few of the windows tasks I received today are actually working. Here is a successful example: | |
| ID: 60147 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
FWIW, this morning my windows machines started getting ATM tasks. Most of these tasks are erroring out. For these tasks, they have been issued many times over too many and failed every time. Looks like a problem with the tasks and not the clients running them. They will eventually work their way out of the system. But a few of the windows tasks I received today are actually working. Here is a successful example: -------------- Welcome Zombie67. If you are looking for more excitement, Climate has implemented OpenIFS. | |
| ID: 60148 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
All openifs tasks are already sent. | |
| ID: 60149 | Rating: 0 | rate:
| |
|
Pop Piasa Send message Joined: 8 Aug 19 Posts: 252 Credit: 458,054,251 RAC: 0 Level Scientific publications | |
...But a few of the windows tasks I received today are actually working. I have one that is working, but I had to add ATMs to my appconfig file to get them to more accurately show the time remaining, due to what Ian pointed out way upthread. https://www.gpugrid.net/forum_thread.php?id=5379&nowrap=true#60041 I now see realistic time remaining. My current appconfig.xml script app_config> This task ran alongside a F@H task (project 18717) on a RTX3060 12GB card without any problem, in case anybody is interested. | |
| ID: 60150 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
Why not | |
| ID: 60151 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
So far, 2 WUs successfully completed, another one running. | |
| ID: 60152 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
it still can't run run.bat | |
| ID: 60153 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
progress reporting is still not working. | |
| ID: 60154 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
progress reporting is still not working. T_p38 were sent before the update so I guess it makes sense that they don't show reporting yet. Is the progress report for the BACE runs good? Is it staying stuck? | |
| ID: 60155 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Yes, BACE looks good. | |
| ID: 60156 | Rating: 0 | rate:
| |
|
Emilio Gallicchio Send message Joined: 23 Mar 23 Posts: 4 Credit: 87,500 RAC: 0 Level Scientific publications | |
|
Hello Quico and everyone. Thank you for trying AToM-OpenMM on GPUGRID. | |
| ID: 60157 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
The python task must tell the boinc client how many ticks are to calculate (MAX_SAMPLES = 341 from *_asyncre.cntl times 22 replica) and the end of each tick. | |
| ID: 60158 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The ATM tasks also record that a task has checkpointed in the job.log file in the slot directory (or did so, a few debug iterations ago - see message 60046). | |
| ID: 60159 | Rating: 0 | rate:
| |
|
Emilio Gallicchio Send message Joined: 23 Mar 23 Posts: 4 Credit: 87,500 RAC: 0 Level Scientific publications | |
|
The GPUGRID version of AToM: # Report progress on GPUGRID progress = float(isample)/float(num_samples - last_sample) open("progress", "w").write(str(progress)) which checks out as far as I can tell. last_sample is retrieved from checkpoints upon restart, so the progress % should be tracked correctly across restarts. | |
| ID: 60160 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
OK, the BACE task is running, and after 7 minutes or so, I see: 2023-03-24 15:40:33 - INFO - sync_re - Started: checkpointing 2023-03-24 15:40:49 - INFO - sync_re - Finished: checkpointing (duration: 15.699278543004766 s) 2023-03-24 15:40:49 - INFO - sync_re - Finished: sample 1 (duration: 303.5407383099664 s) in the run.log file. So checkpointing is happening, but just not being reported through to BOINC. Progress is 3.582% after eleven minutes. | |
| ID: 60161 | Rating: 0 | rate:
| |
|
Emilio Gallicchio Send message Joined: 23 Mar 23 Posts: 4 Credit: 87,500 RAC: 0 Level Scientific publications | |
|
Actually, it is unclear if AToM's GPUGRID version checkpoints after catching termination signals. I'll ask Raimondas. Termination without checkpointing is usually okay, but progress since the checkpoint would be lost, and the number of samples recorded in the checkpoint file would not reflect the actual number of samples recorded. | |
| ID: 60162 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The app seems to be both checkpointing, and updating progress, at the end of each sample. That will make re-alignment after a pause easier, but there's always some over-run, and data lost on restart. It's up to the application itself to record the data point reached, and to be used for the restart, as an integral part of the checkpointing process. | |
| ID: 60163 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Seriously? Only 14 tasks a day? GPUGRID 3/24/2023 9:17:44 AM This computer has finished a daily quota of 14 tasks | |
| ID: 60164 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Seriously? Only 14 tasks a day? The quota adjusts dynamically - it goes up if you report successful tasks, and goes down if you report errors. | |
| ID: 60165 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The T_PTP1B_new task, on the other hand, is not reporting progress, even though it's logging checkpoints in the run.log <active_task> <project_master_url>https://www.gpugrid.net/</project_master_url> <result_name>T_PTP1B_new_23484_23482_T3_2A_1-QUICO_TEST_ATM-0-1-RND3714_3</result_name> <checkpoint_cpu_time>10.942300</checkpoint_cpu_time> <checkpoint_elapsed_time>30.176729</checkpoint_elapsed_time> <fraction_done>0.001996</fraction_done> <peak_working_set_size>8318976</peak_working_set_size> <peak_swap_size>16592896</peak_swap_size> <peak_disk_usage>1318196036</peak_disk_usage> </active_task> The <fraction done> is reported as the 'progress%' figure - this one is reported as 0.199% by BOINC Manager (which truncates) and 0.200% by other tools (which round). This task has been running for 43 minutes, and boinc_task_state.xml hasn't been re-written since the first minute. | |
| ID: 60166 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
| |
| ID: 60167 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
| |
| ID: 60168 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
My BACE task 33378091 finished successfully after 5 hours, under Linux Mint 21.1 with a GTX 1660 Super. | |
| ID: 60169 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Task 27438853 | |
| ID: 60170 | Rating: 0 | rate:
| |
|
Emilio Gallicchio Send message Joined: 23 Mar 23 Posts: 4 Credit: 87,500 RAC: 0 Level Scientific publications | |
Right, probably the wrapper should send a termination signal to AToM. We have of course access to AToM's sources https://github.com/Gallicchio-Lab/AToM-OpenMM and we can make sure that it checkpoints appropriately when it receives the signal. However, I do not have access to the wrapper. Quico: please advise. | |
| ID: 60171 | Rating: 0 | rate:
| |
|
Landjunge Send message Joined: 2 Nov 08 Posts: 3 Credit: 6,291,031,724 RAC: 33,661,780 Level Scientific publications | |
|
Hi, i have some "new_2" ATMs that run for 14h+ yet. Should i abort them? | |
| ID: 60172 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The wrapper you're using at the moment is called "wrapper_26198_x86_64-pc-linux-gnu" (I haven't tried ATM under Windows yet, but can and will do so when I get a moment). 20:37:54 (115491): wrapper (7.7.26016): starting That would put the date back to around November 2015, but I guess someone has made some local modifications. | |
| ID: 60173 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Hi, i have some "new_2" ATMs that run for 14h+ yet. Should i abort them? I have one at the moment which has been running for 17.5 hours. The same machine completed one yesterday (task 33374928) which ran for 19 hours. I wouldn't abort it just yet. | |
| ID: 60174 | Rating: 0 | rate:
| |
|
Landjunge Send message Joined: 2 Nov 08 Posts: 3 Credit: 6,291,031,724 RAC: 33,661,780 Level Scientific publications | |
Hi, i have some "new_2" ATMs that run for 14h+ yet. Should i abort them? thank you. I will let them running =) | |
| ID: 60175 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
And completed. | |
| ID: 60176 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
Seriously? Only 14 tasks a day? Quico, This behavior is intended to block misconfigured computers. In this case it's your Windows version that fails in seconds and being resent until it hits a Linux computer or fails 7 times. My Win computer was locked out of GG early yesterday but all my Linux computers donated until WUs ran out. In this example the first 4 failures all went to Win7 & 11 computers and then Linux completed it successfully: https://www.gpugrid.net/workunit.php?wuid=27438768 And the Win WUs are failing in seconds again with today's tranche. | |
| ID: 60177 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
WUs failing on Linux computers: + python -m pip install git+https://github.com/raimis/AToM-OpenMM.git@172e6db924567cd0af1312d33f05b156b53e3d1c Running command git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git /var/lib/boinc-client/slots/36/tmp/pip-req-build-jsq34xa4 fatal: unable to access '/home/conda/feedstock_root/build_artifacts/git_1679396317102/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placeho/etc/gitconfig': Permission denied error: subprocess-exited-with-error × git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git /var/lib/boinc-client/slots/36/tmp/pip-req-build-jsq34xa4 did not run successfully. │ exit code: 128 ╰─> See above for output. note: This error originates from a subprocess, and is likely not a problem with pip. error: subprocess-exited-with-error https://www.gpugrid.net/result.php?resultid=33379917 | |
| ID: 60183 | Rating: 0 | rate:
| |
|
Landjunge Send message Joined: 2 Nov 08 Posts: 3 Credit: 6,291,031,724 RAC: 33,661,780 Level Scientific publications | |
|
Any ideas why WUs are failing on a linux ubuntu machine with gtx1070? <core_client_version>7.20.5</core_client_version> | |
| ID: 60184 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
(I haven't tried ATM under Windows yet, but can and will do so when I get a moment). Just downloaded a BACE task for Windows. There may be trouble ahead... The job.xml file reads: <job_desc> <unzip_input> <zipfilename>windows_x86_64__cuda1121.zip</zipfilename> </unzip_input> <task> <application>python.exe</application> <command_line>bin/conda-unpack</command_line> <weight>1</weight> </task> <task> <application>Library/usr/bin/tar.exe</application> <command_line>xjvf input.tar.bz2</command_line> <setenv>PATH=$PWD/Library/usr/bin</setenv> <weight>1</weight> </task> <task> <application>C:/Windows/system32/cmd.exe</application> <command_line>/c call run.bat</command_line> <setenv>CUDA_DEVICE=$GPU_DEVICE_NUM</setenv> <stdout_filename>run.log</stdout_filename> <weight>1000</weight> <fraction_done_filename>progress</fraction_done_filename> </task> </job_desc> 1) We had problems with python.exe triggering a missing DLL error. I'll run Dependency Walker over this one, to see what the problem is. 2) It runs a private version of tar.exe: Microsoft included tar as a system utility from Windows 10 onwards - but I'm running Windows 7. The MS utility wouldn't run for me - I'll try this one. 3) I'm not totally convinced of the cmd.exe syntax either, but we'll cross that bridge when we get to it. | |
| ID: 60185 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
First reports from Dependency Walker: | |
| ID: 60186 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Just a note of warning: one of my machines is running a JNK1 task - been running for 13 hours. MAX_SAMPLES = 341 One reason why this needs fixing: I have my BOINC client set up in such a way that it normally fetches the next task around an hour before the current one is expected to finish. Because this one was (apparently) running so fast, it reached that point over five hours ago - and it's still waiting. Sorry Abouh - your next result will be late! | |
| ID: 60188 | Rating: 0 | rate:
| |
|
Freewill Send message Joined: 18 Mar 10 Posts: 13 Credit: 12,377,242,894 RAC: 92,818,842 Level Scientific publications | |
|
I also noticed this latest round of BACE tasks have become much longer to run on my GPUs. Some are hitting > 24 hrs. I am going to stop taking new ones unless the # samples/task is trimmed down. | |
| ID: 60189 | Rating: 0 | rate:
| |
|
[SG] Felix Send message Joined: 29 Jan 16 Posts: 11 Credit: 32,223,035 RAC: 1 Level Scientific publications | |
|
I had this one running for about 8 hours, but then i had to shut down my computer. | |
| ID: 60190 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Forget about a re-start, these WUs cannot even take a suspension. I suspended my computer and this WU collapsed. | |
| ID: 60191 | Rating: 0 | rate:
| |
|
[SG] Felix Send message Joined: 29 Jan 16 Posts: 11 Credit: 32,223,035 RAC: 1 Level Scientific publications | |
|
i'm a bit surprised right now, i looked at the resend, it was successfully completed in just over 2 minutes, how come? the computer has more WUs that were successfully completed in such a short time. Am I doing something wrong? | |
| ID: 60192 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I also noticed this latest round of BACE tasks have become much longer to run on my GPUs. Some are hitting > 24 hrs. I am going to stop taking new ones unless the # samples/task is trimmed down. I agree, the 4-6hr runs are much better. ____________ | |
| ID: 60193 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
I have task that reached 100% an hour ago, which means it is suppose to be finished, but it's still running............. | |
| ID: 60194 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
My last ATM tasks spent at least a couple of hours at the 100% completion point. | |
| ID: 60195 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
That's a mute point now. It errored out. | |
| ID: 60196 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
It looks like you got bit by a permission error. | |
| ID: 60197 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
It looks like you got bit by a permission error. The Boinc version is 7.20.7. https://www.gpugrid.net/hosts_user.php?userid=19626 | |
| ID: 60198 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
Another task failed. | |
| ID: 60199 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The output file will always be absent if the task fails - it doesn't get as far as writing it. The actual error is in the online report: ValueError: Energy is NaN. ('Not a Number') That's a science problem - not your fault. | |
| ID: 60200 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
I've seen that you are unhappy with the last batch of runs. Seeing that they take too much time. I've been playing to divide the runs in different steps to get a sweet spot that you're happy with it and it's not madness for me to organize all this runs and re-runs. I'll backtrack to the previous setting we had before. Apologies for that.
I'll ask Raimondas about this and the other things that have been mentioned since he's the one taking care of this issue. | |
| ID: 60201 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
I've read some people mentioning that the reporter doesn't work or that it goes over 100%. Does it work correctly for someone? | |
| ID: 60202 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
I've read some people mentioning that the reporter doesn't work or that it goes over 100%. Does it work correctly for someone? It varies from task to task - or, I suspect, from batch to batch. I mentioned a specific problem with a JNK1 task - task 33380692 - but it's not a general problem. I suspect that it may have been a specific problem with setting the data that drives the progress %age calculation - the wrong expected 'total number of samples' may have been used. | |
| ID: 60203 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
I've read some people mentioning that the reporter doesn't work or that it goes over 100%. Does it work correctly for someone? This one is a rerun, meaning that 2/3 of the run were previously simulated. Maybe it was expecting to start from 0 samples and once it saw that we're at 228 from the beginning, it got confused. I'll comment that. PS: But others runs have been reporting correctly? | |
| ID: 60204 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
https://www.gpugrid.net/result.php?resultid=33382097 | |
| ID: 60205 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
see post https://www.gpugrid.net/forum_thread.php?id=5379&nowrap=true#60160 | |
| ID: 60206 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Or possibly progress = float(isample - last_sample)/float(num_samples - last_sample) if you want a truncated resend to start from 0% - but might that affect paused/resumed tasks as well? | |
| ID: 60207 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
None of my WUs from yesterday completed. Please issue a server abort and eliminate all these defective WUs before releasing a new set. Otherwise defects will keep wasting 8 computers time for days to come. | |
| ID: 60208 | Rating: 0 | rate:
| |
|
kksplace Send message Joined: 4 Mar 18 Posts: 53 Credit: 1,816,356,749 RAC: 6,127,466 Level Scientific publications | |
The problem is not the time they take to run. I agree with this. I had one error out on a restart two days ago after reaching nearly 100% due to no checkpoints. Not only that, but it then only showed 37 seconds of CPU time, so it doesn’t show what really happened. My latest one did complete but showed no check points. Therefore the long run time of is more of a high risk for a potential interruption. | |
| ID: 60209 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
None of my WUs from yesterday completed. Please issue a server abort and eliminate all these defective WUs before releasing a new set. Otherwise defects will keep wasting 8 computers time for days to come. ______________ My problem with re-start and suspending is, these WUs are GPU intensive. As soon as one of these WUs pops up, my GPU fans let me know to do maintenance of the cooling system. I have laptops. I cannot take a blower on a running system. Now this WU for example has run for 21 hours and is at 34.5%. task 27440346 Edit. It is still running fine. | |
| ID: 60210 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
It looks like you got bit by a permission error. Not your fault, I got a couple errored tasks that duplicated yours. Just a bad batch of tasks went out. | |
| ID: 60211 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
I have problem with cmd. It exits with code 1 in 0 seconds. | |
| ID: 60212 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I've got another very curious one. | |
| ID: 60213 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
None of my WUs from yesterday completed. Please issue a server abort and eliminate all these defective WUs before releasing a new set. Otherwise defects will keep wasting 8 computers time for days to come. _____________________________ The above-mentioned WU is at 71.8% and has been running now for 1 Day and 20 hours. It is still running fine and as I cannot read log files, you can go over what it has been doing once finished. I have marked no further WUs from GPUgrid. I will re-open after updates, etc which I have forced-paused. | |
| ID: 60214 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Looked at the errored tasks list on my account this morning and see another slew of badly misconfigured tasks went out. | |
| ID: 60215 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
None of my WUs from yesterday completed. Please issue a server abort and eliminate all these defective WUs before releasing a new set. Otherwise defects will keep wasting 8 computers time for days to come. ________________ Completed after two days, four hours and forty minutes. Now there is another problem. One task is showing 100% completed for the last four hours but it is still using the CPU for something. Not the GPU. The elapsed clock is still ticking but the remaining is zero. | |
| ID: 60216 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
This task PTP1B_23471_23468_2_2A-QUICO_TEST_ATM-0-1-RND8957_1 is currently doing the same on this host. | |
| ID: 60218 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
This task reached "100% complete" in about 7 hours, and then ran for an additional 7 hours +, before actually finishing. | |
| ID: 60219 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Anybody got that beat?????? The task I reported in Message 60213 (14:55 yesterday) is still running. It was approaching 100% when I went to bed last night, and it's still there this morning. I'll go and check it out after coffee (I can't see the sample numbers remotely). As soon as I wrote that, it uploaded and reported! Ah well, my other Linux machine has got one in the same state. | |
| ID: 60220 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
None of my WUs from yesterday completed. Please issue a server abort and eliminate all these defective WUs before releasing a new set. Otherwise defects will keep wasting 8 computers time for days to come. _________________ Just woke up. The task was finished. Sent it home. task 27441741 | |
| ID: 60223 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
OK, it's the same story as yesterday. This task: | |
| ID: 60224 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
OK, it's the same story as yesterday. This task: I believe it's what I imagined. From the manual division I was doing before I was splitting some runs in 2/3 steps: 114 - 228 - 341 samples. If the job ID has a 2A/3A it's most probably that it's starting from a previous checkpoint and the progress report is going crazy with it. I'll pass this on to Raimondas to see if he can get a look at it. Our priority first is to be able to that these job divisions are done automatically like ACEMD does, that way we can avoid these really long jobs for everyone. Doing this manually makes it really hard to track all the jobs and the resends. So I hope that in the next days everything goes smoother. | |
| ID: 60225 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Thanks. Now I know what I'm looking for (and when), I was able to watch the next transition. | |
| ID: 60226 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
The %age intervals match the formula in Emilio Gallicchio's post 60160 (115/(341-114)), but I can't see where the initial big value of 50.983 comes from. 115/(341-114) = 0.5066 = 50.66% strikingly close. maybe "BOINC logic" in some form of rounding. but it's pretty clear that the 50% value is coming from this calculation. ____________ | |
| ID: 60227 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I thought I'd checked that, and got a different answer, but my mouse must have slipped on the calculator buttons. | |
| ID: 60228 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
After that, it failed after 3 hours 20 minutes with a 'ValueError: Energy is NaN' error. Never mind - I tried. | |
| ID: 60229 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
C:/Windows/system32/cmd.exe command creates c:\users\frolo\.exe\ folder. | |
| ID: 60230 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Thanks. Now I know what I'm looking for (and when), I was able to watch the next transition. The first 114 samples should be calculated by: T_PTP1B_new_20669_2qbr_23472_1A_3-QUICO_TEST_ATM-0-1-RND2542_0.tar.bz2 I've been doing all the division and resends manually and we've been simplifying the naming convention for my sake. Now we are testing a multiple_steps protocol just like in AceMD which should help ease things and I hope mess less with the progress reporter. | |
| ID: 60233 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Thanks. Be aware that out here in client-land we can only locate jobs by WU or task ID numbers - it's extremely difficult to find a task by name unless we can follow an ID chain. | |
| ID: 60234 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Yeah I'm sorry about that. I'm trying to learn as I go. | |
| ID: 60237 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Two downloaded, the first has reached 6% with no problems. | |
| ID: 60238 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Yeah I'm sorry about that. I'm trying to learn as I go. ____________________ It is un-stable tasks, re-start problems, suspend problems. Quite a few of us have done year-plus runs on Climate. 24-hour runs are no problem. | |
| ID: 60239 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
deleted | |
| ID: 60240 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I believe I just finished one of these ATMbeta tasks. | |
| ID: 60241 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
I believe I just finished one of these ATMbeta tasks. Same for me with Linux. Since there's no checkpointing I didn't bother to test suspending. I think all windows WUs failed. | |
| ID: 60242 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
My current two ATM betas both have MAX_SAMPLES: +70 - but one started at 71, and the other at 141. | |
| ID: 60243 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
My current two ATM betas both have MAX_SAMPLES: +70 - but one started at 71, and the other at 141. My observations are same. When the units download, the estimated finish time reads 606 days. https://www.gpugrid.net/results.php?hostid=534811&offset=0&show_names=0&state=0&appid=45 So far, in this batch, 3 WUs completed successfully, 1 error and 1 is crunching, on a windows 10 machine. The units all crash on my other computer, which runs windows 7 and is rather old, 13 years. Maybe, it's time to retire it from this project, though it still runs well on other projects, like Einstein and FAH. https://www.gpugrid.net/results.php?hostid=544232&offset=0&show_names=0&state=0&appid=45 | |
| ID: 60244 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
My first ATM beta on Windows10 failed after some 6 hours :-( | |
| ID: 60245 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
anyone an idea what exactly the problem was? It says ValueError: Energy is NaN. A science error (impossible result), rather than a computing error. | |
| ID: 60246 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Potentially, it could also be due to instability in overclocks, where applicable. I know the ACEMD3 tasks are susceptible to a “particle coordinate is NaN” type error from too much overclocks. | |
| ID: 60247 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Potentially, it could also be due to instability in overclocks, where applicable. I know the ACEMD3 tasks are susceptible to a “particle coordinate is NaN” type error from too much overclocks. thanks for this thought; it could well be the case. For some time, this old GTX980TI has no longer followed the settings for GPU clock and Power target, in the old NVIDIA Inspector as well as in the newer Afterburner. Hence, particularly with ATM tasks I noticed an overclocking from default 1152MHz up to 1330MHz. Not all the time, but many times. I now experimented and found out that I can control the GPU clock by reducing the fan speed, with setting the GPU temperature at a fixed value and setting a check at "priorize temperature". So the clock now oscillates around 1.100MHz most of the time. I will see whether the ATM tasks now will fail again, or not. | |
| ID: 60248 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
My atm beta tasks crash. | |
| ID: 60249 | Rating: 0 | rate:
| |
|
ZUSE Send message Joined: 10 Jun 20 Posts: 7 Credit: 491,165,897 RAC: 108,671 Level Scientific publications | |
|
me too. | |
| ID: 60250 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Something in your Windows configuration has a problem running cmd.exe and calling the run.bat file. Windows barfs on the 0x1 exit error. | |
| ID: 60251 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Another thing that can be possible is that your system re-started after an update or you suspended it. | |
| ID: 60254 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
The ATM tasks are just like the acemd3 tasks in that they can't be interrupted or restarted without erroring out. Unlike the acemd3 tasks which can be restarted on the same device, the ATM tasks can't be restarted or interrupted at all. They exit immediately if restarted. | |
| ID: 60256 | Rating: 0 | rate:
| |
|
STARBASEn Send message Joined: 17 Feb 09 Posts: 91 Credit: 1,603,303,394 RAC: 0 Level Scientific publications | |
The ATM tasks are just like the acemd3 tasks in that they can't be interrupted or restarted without erroring out. Unlike the acemd3 tasks which can be restarted on the same device, the ATM tasks can't be restarted or interrupted at all. They exit immediately if restarted. I agree, I have lost quite a few hours on WU's that were going to complete because I had perform reboots and lost them. Is anyone addressing this issue yet? | |
| ID: 60257 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Haven't heard or seen any comments by any of the devs. The acemd3 app hasn't been fixed in two years. And that is an internal application by Acellera. | |
| ID: 60258 | Rating: 0 | rate:
| |
|
ZUSE Send message Joined: 10 Jun 20 Posts: 7 Credit: 491,165,897 RAC: 108,671 Level Scientific publications | |
|
it is just interesting that acemd3 runs through and ATM does not. errors appear after a few minutes | |
| ID: 60259 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
it is just interesting that acemd3 runs through and ATM does not. errors appear after a few minutes If you're time-slicing with another GPU project that will cause a fatal "computation error" when BOINC switches between them. | |
| ID: 60260 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Task failed. | |
| ID: 60261 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
Beta or not...how can a Project send out tasks with this length of runtime and not have any checkpointing of some sort. | |
| ID: 60264 | Rating: 0 | rate:
| |
|
STARBASEn Send message Joined: 17 Feb 09 Posts: 91 Credit: 1,603,303,394 RAC: 0 Level Scientific publications | |
|
I concur with bluestang, some of those likely successful WU's I lost had 20+ hours getting wasted because of a necessary reboot. Project owners should make some sort of a fix a priority. | |
| ID: 60266 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Or just acknowledge you aren't willing to accept the project limitations and move onto other gpu projects that fit your usage conditions. | |
| ID: 60267 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Or just acknowledge you aren't willing to accept the project limitations and move onto other gpu projects that fit your usage conditions. ________________ Do you know what the problem is? Quico has not understood what Abou did at the very start. I am pretty sure whatever it is if he brings it to the thread he will find an answer. There are a lot of people on the thread and one of them is you, who are willing to help to the best of their ability. Experts. I have paused all Microsoft Updates for five weeks which seems to trigger the rest of the updates, like Intels. Just for these WUs. | |
| ID: 60268 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
But abouh's app is different from Quico's. They use different external tools. You can't apply the same fixes that abouh did for Quico's app. | |
| ID: 60269 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
But abouh's app is different from Quico's. They use different external tools. You can't apply the same fixes that abouh did for Quico's app. ___________________ I am not saying anything but I agree with the sentiments of some. Maybe, some of us can play with AToM libs. | |
| ID: 60270 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Having looked into the internal logging of Quico's tasks in some detail because of the progress %age problem, it's clear that it goes through the motions of writing a checkpoint normally - 70 times per task for the recent short runs, 341 per task for the very long ones. That's about once every five minutes on my machines, which would be perfectly acceptable to me. | |
| ID: 60271 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Impressive. | |
| ID: 60273 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
anyone any idea why this task: | |
| ID: 60274 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
ValueError: Energy is NaN. IOW Not a number. | |
| ID: 60275 | Rating: 0 | rate:
| |
|
[AF>FAH-Addict.net]toTOW Send message Joined: 28 Oct 10 Posts: 9 Credit: 25,781,299 RAC: 0 Level Scientific publications | |
|
All WUs seems to be failing the same way with missing files : | |
| ID: 60276 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
We see this frequently with misconfigured tasks. Researcher does a poor job updating the task generation template when configuring for new tasks. | |
| ID: 60277 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov  Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
seems to be failing the same way with missing files Same here: https://www.gpugrid.net/result.php?resultid=33406558 But first failed among dozen successful completed. | |
| ID: 60278 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Wastes time and resources for every one. Well, as long as a tasks fails within a few minutes (I had a few such ones yesterday), I think it's not that bad. But I had one, day before yesterday, which failed after some 5-1/2 hours - which is not good :-( | |
| ID: 60279 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
task 27451592 | |
| ID: 60281 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Thought I'd run a quick test to see if there was any progress on the restart front. Waited until a task had just finished, and let a new one start and run to the first checkpoint: then paused it, and waited while another project borrowed the GPU temporarily. Running command git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git /hdd/boinc-client/slots/2/tmp/pip-req-build-368b4spp fatal: unable to access '/home/conda/feedstock_root/build_artifacts/git_1679396317102/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placeho/etc/gitconfig': Permission denied That doesn't sound very hopeful. It's still a problem. | |
| ID: 60282 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
task 27451592 _______________________________ task 27451763 task 27451117 task 27452961 Completed and validated. No errors as yet. I dare not even sneeze near them. All updates are off. | |
| ID: 60283 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
This "OFF" in the WU points towards Python. "AToM" also has something to do with Python. | |
| ID: 60284 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I think 'Python' is a programming language, and 'AToM' is a scientific program written in that language. | |
| ID: 60285 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Well, as long as a tasks fails within a few minutes (I had a few such ones yesterday), I think it's not that bad. what I noticed lately on my machines is: when ATM tasks fail, mostly after 60-90 seconds. And stderr always says: FileNotFoundError: [Errno 2] No such file or directory: 'thrombin_noH_2-1a-3b_0.xml' 23:18:10 (18772): C:/Windows/system32/cmd.exe exited; CPU time 18.421875 see here: https://www.gpugrid.net/result.php?resultid=33409106 | |
| ID: 60286 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
task 27451592 task 27452387 task 27452312 task 27452961 task 27452969 completed and validated. One task in error, task 33410323 | |
| ID: 60287 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Similar story. MCL1_49_35_4-QUICO_ATM_OFF_STEPS-0-5-RND5875_2 failed in 44 seconds with FileNotFoundError: [Errno 2] No such file or directory: 'MCL1_pmx-49-35_0.xml' | |
| ID: 60289 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Has anyone noticed the WUs with 'Bace' in their name, they show progress as 100% but the Time Elapsed counter is still ticking. Task Manager shows the task is still busy computing. This goes on for hours on end and one Task went up to 24 Hrs in this state. | |
| ID: 60290 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Similar story. MCL1_49_35_4-QUICO_ATM_OFF_STEPS-0-5-RND5875_2 failed in 44 seconds with same here, about 1 hour ago: FileNotFoundError: [Errno 2] No such file or directory: 'MCL1_pmx-30-40_0.xml' such errors, happening often enough, may show some kind of sloppy tasks configuration ? | |
| ID: 60291 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Similar story. MCL1_49_35_4-QUICO_ATM_OFF_STEPS-0-5-RND5875_2 failed in 44 seconds with __________________ Same here. The Task with 'MCLI' in their name lasted 18 seconds only. task 33411408 | |
| ID: 60292 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
This WU with 'Jnk1' in it, lasted ten seconds. | |
| ID: 60293 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
This 'MCL1' has been running steadily for the last hour. But it is showing progress as 100% while the elapsed clock is ticking. Task Manager shows it is busy. | |
| ID: 60294 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
But it is showing progress as 100% So with all ATM WUs, this is "normal". Perhaps later the devs will be able to fix it. So there is no need to be surprised by this fact in every post -_- | |
| ID: 60295 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
This WU with 'Jnk1' in it, lasted ten seconds. _______________ Completed and validated. No. For some reason, people are aborting, like this WU 'thrombin'. We normally watch the progress report. Instead, check the Task Manager. If there is a heartbeat, let it run. | |
| ID: 60296 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
This 'MCL1' has been running steadily for the last hour. But it is showing progress as 100% while the elapsed clock is ticking. Task Manager shows it is busy. _______________ Completed and validated. Auram? | |
| ID: 60297 | Rating: 0 | rate:
| |
|
When tasks are available how much percentage of CPU do they require, does the CPU usage fluctuate like the other Python tasks? | |
| ID: 60301 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
When tasks are available how much percentage of CPU do they require, does the CPU usage fluctuate like the other Python tasks? One CPU is plenty for these tasks. It doesn't need a full GPU so I run Einstein, Milkyway or OPNG with it. Problem is if BOINC time slices it the ATM WU will fail when it gets restarted. Unless it time-sliced due to the final step (zipping up maybe?) after several hours. Then when it UL and Report as Valid. The best way to assure these ATM WUs succeed is to not run a different project to avoid having BOINC switch the GPU and crash it when it restarts. Running 2 ATM WUs per GPU or an ACEMD+ATM is ok since it doesn't switch away. | |
| ID: 60302 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
This 'MCL1' has been running steadily for the last hour. But it is showing progress as 100% while the elapsed clock is ticking. Task Manager shows it is busy._______________ Yes the failed WU is my Rig-11 which is having intermittent failures/reboots due to a MB/GPU issue of unknown origin. I've swapped GPUs several times and the problem stays with the Rig-11 MB so it's not a bad GPU. If I leave the GPU idle the CPU runs WUs fine. Einstein and Milkyway don't seem to cause the problem but Asteroids, GG and maybe OPNG do at random intervals. Also it might be time-slicing that I described in my penultimate reply. It's probably time to scrap the MB. Since most are designed for gamers they stuff too much junk on them and compromise their reliability. | |
| ID: 60303 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Looks like all of today's WUs are failing: FileNotFoundError: [Errno 2] No such file or directory: 'CDK2_new_2_edit-1oiy-1h1q_0.xml' It dumbfounds me why they still have it set to fail 7 times. If they fail at the end then that's several days of compute time wasted. Isn't two failures enough? | |
| ID: 60304 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
I had two fail in this way, but the rest (20+ or so) are running fine. Certainly not "all" of them. | |
| ID: 60305 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Strange enough, about 2 hours ago one of my rigs downloaded 2 ATM tasks, while Python tasks were running. | |
| ID: 60306 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I think the beta toggle in preferences is 'sticky' in the scheduler. | |
| ID: 60307 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
Strange enough, about 2 hours ago one of my rigs downloaded 2 ATM tasks, while Python tasks were running. I think ATMbeta is controlled by Run test applications? | |
| ID: 60308 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I think ATMbeta is controlled by oh, this might explain. While I unchecked "ATM beta" I neglected to uncheck "Run test applications" | |
| ID: 60309 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
This WU had me error out for NAN at 913 seconds. I never overclock my GPUs and power limited this 2080 Ti to 180 W since GPUs are notorious for wasting energy. This NAN error is due setting the calculation boundaries wrong. | |
| ID: 60310 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
Hello Quico, | |
| ID: 60312 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
File "/var/lib/boinc-client/slots/34/lib/python3.9/site-packages/openmm/app/statedatareporter.py", line 365, in _checkForErrors https://www.gpugrid.net/workunit.php?wuid=27469907raise ValueError('Energy is NaN. For more information, see https://github.com/openmm/openmm/wiki/Frequently-Asked-Questions#nan') ValueError: Energy is NaN. Watched a WU finish and it spent 6 minutes out of 313 minutes on 100%. No checkpointing. Has it been confirmed that the calculation boundaries are correct and not the cause of the NaN errors? | |
| ID: 60319 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
I, too, had such an error after the task had run for 7.885 seconds: | |
| ID: 60320 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Wow! Six minutes is a significant improvement over the hours it was taking before. Just don't give it a kick and abort. | |
| ID: 60321 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
Too bad, not so simple after all. I wrote the checkpoint tag in the job.xml in the project directory under Windows and after two samples suspend/resume and again the job started with the first task and died with python pip. | |
| ID: 60322 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I, too, had such an error after the task had run for 7.885 seconds: this time, the task errored out after 16.400 seconds :-( https://www.gpugrid.net/result.php?resultid=33442242 | |
| ID: 60333 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
It feels like there's at least four categories of ATMbeta WUs running simultaneously. | |
| ID: 60335 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
My Nation like many others has gone into a default situation. The most expensive item is the supply of electricity and they are frequently switching off the grid without informing us. | |
| ID: 60336 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Still no checkpointing. | |
| ID: 60352 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
If there is a storm and electricity go, WU crashes. I know that Boincer's do not do a re-start for months on end but I have to do a re-start. WU crashes. If the GPU updates or the System updates, the WU crashes. If the cat plays with the keyboard, the WU crashes. | |
| ID: 60353 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
Who cares. No, it's not about who cares. This is about which of the project employees has the knowledge and resources to implement the necessary functionality, and which of them has the time for this. And as you should understand, they don't make decisions there on their own, it's not a hobby. The necessary specialists can now be involved in other, more priority projects for the institute, and neither we nor the employees themselves can influence this. Deal with it. Nothing will change from the number of tearful posts about the problem, no matter how much someone would like it. Unless, of course, the goal is once again just to let off steam somewhere because of indignation. | |
| ID: 60354 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Task TYK2_m44_m55_5_FIX-QUICO_ATM_Sage_xTB-0-5-RND2847_0 (today): FileNotFoundError: [Errno 2] No such file or directory: 'TYK2_m44_m55_0.xml' Later - CDK2_miu_m26_4-QUICO_ATM_Sage_xTB-0-5-RND8419_0 running OK. | |
| ID: 60357 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
And a similar batch configuration error with today's BACE run, like 08:05:32 (386384): wrapper: running bin/bash (run.sh) (five so far) Edit - now wasted 20 of the things, and switched to Python to avoid quota errors. I should have dropped in to give you a hand when passing through Barcelona at the weekend! | |
| ID: 60358 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
I cannot resource share ATMBeta with other projects because it is stopped to run other projects. Ends up with an error. | |
| ID: 60359 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
And a similar batch configuration error with today's BACE run, like Same for Win apps: https://www.gpugrid.net/result.php?resultid=33475629 https://www.gpugrid.net/results.php?userid=101590 Sad : / | |
| ID: 60360 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I cannot resource share ATMBeta with other projects because it is stopped to run other projects. Ends up with an error. set all other GPU projects to resource share of 0, then they wont run at all when you have ATM work. ____________ | |
| ID: 60361 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
many of the recent ATMs errored out after not even a minute, stderr says: | |
| ID: 60362 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Same equivalent type of error in Linux for a great many tasks. | |
| ID: 60363 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Got a collection of twenty-one errored tasks. Suspended work fetch on that computer. The other is busy with Abous WU. | |
| ID: 60364 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Now these are doing it as well: MCL1_m28_m47_1_FIX-QUICO_ATM_Sage_xTB-0-5-RND0954_0 18:09:56 (394275): wrapper: running bin/bash (run.sh) The experimenters and/or staff have got to get a grip on this - you are wasting everybody's time and electricity. BOINC is very unforgiving: you have to get it 100% exact, all at the same time, every time. It's worth you taking a pause after each new batch is prepared, and then going back and proof-reading the configuration. Five minutes spent checking would probably have meant getting some real research results over the weekend: now, nothing will probably work until Monday (and I'm not holding my breath then, either). | |
| ID: 60365 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
Now these are doing it as well: MCL1_m28_m47_1_FIX-QUICO_ATM_Sage_xTB-0-5-RND0954_0 Exactly! When you have more Tasks that Error (277) than Valid (240) ... that is pretty damn sad! | |
| ID: 60366 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
The experimenters and/or staff have got to get a grip on this - you are wasting everybody's time and electricity. + 1 | |
| ID: 60369 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Got a collection of twenty-one errored tasks. Suspended work fetch on that computer. The other is busy with Abous WU. ___________ Abous, WU finished and I got one ATMBeta. It lasted all of one minute and three seconds. Suspended work fetch on this computer also. Validated two ATMBeta, error twenty-two. | |
| ID: 60370 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Maybe someone can answer a question I have. After running ATMBeta, Einstein starts but it reports, GPU is missing. How does this happen? | |
| ID: 60371 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
atmbeta likely has nothing to do with it. | |
| ID: 60372 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
atmbeta likely has nothing to do with it. _____________________________ Thank you. I have just finished reinstalling Windows and now the drivers. | |
| ID: 60373 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Clean Windows install and drivers install. | |
| ID: 60375 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
And a similar batch configuration error with today's BACE run, like Yes, big mess up on my end. More painful since it happened to two of the sets with more runs. I just forgot to run the script that copies the run.sh and run.bat files to the batch folders. It happened to 2/8 batches but yeah, big whoop. Apologies on that. The "fixed" runs should be sent soon. The "missing *0.xml" errors should not happen anymore too. Regarding checkpoint, at least I, cannot do much more than pass the message which I have done several times. Again, sorry for this. I can understand it to be very annoying. | |
| ID: 60376 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Thanks for reporting back. | |
| ID: 60378 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
Extrapolated execution times for several of my currently running "BACE_" and "MCL1_" WUs are pointing to be longer than other previous batches. | |
| ID: 60379 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Agreed. My first BASE of the current batch ran for 20 minutes per sample, compared with previous batches which ran at speeds down as low as 5 minutes per sample. It's touch and go whether they will complete within 24 hours (GTX 1660 Ti/super). | |
| ID: 60380 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Extrapolated execution times for several of my currently running "BACE_" and "MCL1_" WUs are pointing to be longer than other previous batches. I am afraid that just now I am confronted with such a case: the file has size of 719 MB, and it does not upload, just backing off all the time :-( WTF is this? Did it run 15 hours on a RTX3070 just for nothing? | |
| ID: 60381 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I'm in the same unfortunate situation with too large an upload. | |
| ID: 60382 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
Now have 15 BACE tasks backed up because server not accepting the file size. | |
| ID: 60383 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I'd hang on to them for a day or two - it can be fixed, if the right person pulls their finger out. | |
| ID: 60384 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I'd hang on to them for a day or two - it can be fixed, if the right person pulls their finger out. Although I doubt that this will happen :-( | |
| ID: 60385 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
previous instances of this problem you could abort the large upload and it will report fine and you still get credit most of the time. | |
| ID: 60386 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I'd like to think that all that bandwidth carries something of value to the researchers - that would be the main point of it. | |
| ID: 60387 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i thought one of the researchers said they don't need this file. | |
| ID: 60388 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
I just aborted such a completed task which then showed as ready to report. Reported it, but zero credit :-( | |
| ID: 60389 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
i thought one of the researchers said they don't need this file. Perhaps Quico could confirm that, since we seem to have his attention? | |
| ID: 60390 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
As some compensation for the BACE tasks, I'm seeing the MCL1 sage seasoned tasks reporting | |
| ID: 60391 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
OK, confirmed - it is still the Apache problem. Tue 09 May 2023 15:06:15 BST | GPUGRID | [http] [ID#15383] Received header from server: HTTP/1.1 413 Request Entity Too Large File (the larger of two) is 754.1 MB (Linux decimal), 719.15 MB (Boinc binary). At this end, we have two choices: 1) Abort the data transfer, as Ian suggests. 2) Wait 90 days for somebody to find the key to the server closet. Quico? | |
| ID: 60392 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
is this problem only with "BACE..." tasks, or has anyone seen it with other types of task as well? | |
| ID: 60393 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
Just BACE tasks affected. I've now aborted 14 tasks and half were credited. | |
| ID: 60395 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Just BACE tasks affected. I've now aborted 14 tasks and half were credited. really strange, isn't it? What's the criterion for granting credit or not granting credit ??? I now aborted two such BACE tasks which could not upload. For one I got credit, for the other one it said "upload failure" - real junk :-((( 15 hours on a RTX3070 just for NOTHING :-((( | |
| ID: 60396 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I just aborted my too large upload and got some credit for it. Missed the 50% bonus because of holding onto it for too long. | |
| ID: 60397 | Rating: 0 | rate:
| |
|
kksplace Send message Joined: 4 Mar 18 Posts: 53 Credit: 1,816,356,749 RAC: 6,127,466 Level Scientific publications | |
|
When I attempt to Abort two of these WUs, nothing seems to happen at all. Both tasks still show "Uploading" and the Transfers page still shows them at 0%. I have tried "Retry Now" on the Transfers page several times (each) to no avail. Should I instead "Abort Transfer"? | |
| ID: 60398 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Yes, you want to go to the Transfers page, select the tasks that are in upload backoff and "Abort Transfer" | |
| ID: 60399 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
Way to go GPUgrid. Sure are on a roll lately with the complete utter mess ups. | |
| ID: 60400 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
during last night, two of my machines downloaded and startet "Bace" tasks (first letter in upper case, the following ones in lower case). | |
| ID: 60401 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
during last night, two of my machines downloaded and startet "Bace" tasks (first letter in upper case, the following ones in lower case). https://www.gpugrid.net/workunit.php?wuid=27494001 Bace Unit was successful. See above link. If you run them, watch the elapsed time and progress rate, and you will know in a few minutes, how they will go. | |
| ID: 60402 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
during last night, two of my machines downloaded and startet "Bace" tasks (first letter in upper case, the following ones in lower case). See examples: This one is running well and should finish ok in a few hours. I am running two units simultaneously: https://www.gpugrid.net/workunit.php?wuid=27494007 This one was running long and I aborted: https://www.gpugrid.net/workunit.php?wuid=27492188 This one was probably good and I shouldn't have aborted it: https://www.gpugrid.net/workunit.php?wuid=27494031 In the BOINC manager, highlight the unit and click the properties button on the left, and its progress rate will tell you whether its good or not. | |
| ID: 60403 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
OK, confirmed - it is still the Apache problem. That's weird. I'll get a look. But this shouldn't happen so cancel the BACE (uppercase) runs. I'll have a look on how to do it from here. With the last implentation there shouldn't be such related file-size issues. All bad/bug jobs should be cancelled by now. | |
| ID: 60404 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
This seems like the clearest web advice: | |
| ID: 60405 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
OK, confirmed - it is still the Apache problem. this is not something new from this project. this has been a recurring issue from time to time. seems to pop up about every year or so whenever the result files get so large for one reason or another. so don't feel bad if you are unable to find the setting to fix the file size limit. no one else from the project has been able to for the last several years. why are the result files so large? 500+MB. that's the root cause of the issue. do you need the data in these files? if not, why are they being created? ____________ | |
| ID: 60406 | Rating: 0 | rate:
| |
|
bibi Send message Joined: 4 May 17 Posts: 14 Credit: 10,610,079,643 RAC: 19,263,644 Level Scientific publications | |
|
This files hold the results from the last run, i.e. sample 1 to 70 to start the next run with sample 71 to 140. There are the checkpoint data. | |
| ID: 60407 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
OK, confirmed - it is still the Apache problem. The heavy files are the .dcd which technically I don't really need to obtain to perform the final free energy calculation but it's necessary in case something weird is happening and we want to revisit those frames. .dcd files contains the information and coordinates of all the system atoms but uncompressed. Since there are other trajectory formats, such as .xtc, that compress this data resulting in much lower filesizes we asked to implement the fileformat into OpenMM. As far as I know this has been implemented in our lab but needs the final approval of the "higher-ups" to get it running and then modify ATM to process trajectory files with .xtc. Nevertheless, this shouldn't have happened (it run OK in other instances with BACE) and apologise for this. | |
| ID: 60408 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I resolved my issue by spoofing client_state.xml - I said the over-size file had completed uploading, and that the task was ready to report. The server accepted it as valid. | |
| ID: 60409 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
"ValueError: Energy is NaN" is back quite often :-( | |
| ID: 60410 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
Looks like the Progress bar has stopped working again, all quickly pegged at 100%. | |
| ID: 60411 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I noticed that too. It was working for a while, then today's work it's back to 100% almost immediately. | |
| ID: 60412 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Remind yourselves of my explanation at message 60315. | |
| ID: 60413 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
I just notice that on one of my machines 2 "BACE" tasks are being processed, plus a third one is in waiting position. | |
| ID: 60414 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Why? I am uploading. | |
| ID: 60415 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
Remind yourselves of my explanation at message 60315. One would think that having figured out how to get it working nearly normal they'd maintain that level of proficiency instead of reverting back to the beginning. Writing a BKM (Best Known Method) and checking the boxes when creating new work might prevent having to rediscover everything everywhere all at once. | |
| ID: 60416 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The difference between 0-5 and n-5 has been consistent throughout - there hasn't been a "fix and revert". Just new data runs starting from 0 again. | |
| ID: 60417 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
+1 | |
| ID: 60420 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Quico said on May 10th: With the last implentation there shouldn't be such related file-size issues. Last night, another BACE upload got stuck because of file size 719 MB :-( How come? | |
| ID: 60421 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
|
The number of failures due to Computational Errors is skyrocketing and shamefully they still require 7 donors to fail before recognizing it. | |
| ID: 60422 | Rating: 0 | rate:
| |
|
Aurum Send message Joined: 12 Jul 17 Posts: 400 Credit: 13,812,064,882 RAC: 30,118,441 Level Scientific publications | |
The difference between 0-5 and n-5 has been consistent throughout - there hasn't been a "fix and revert". Just new data runs starting from 0 again. So Progress bars jumping to 100% rendering them useless is proper behavior? | |
| ID: 60423 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
So Progress bars jumping to 100% rendering them useless is proper behavior? No, it's "unfixed" behaviour, hopefully on the 'To do' list. | |
| ID: 60424 | Rating: 0 | rate:
| |
|
[FVG] pima1965 Send message Joined: 20 Jan 10 Posts: 4 Credit: 3,071,430,364 RAC: 349,993 Level Scientific publications | |
|
Good evening, only on one of my PCs with Windows 11, I7-13700KF and RTX 2080 Ti, none of the GPUGRID ATMbeta tasks (CUDA 1121) can be processed. By now more than a hundred have ended after a few tens of seconds. Other tasks (for example based on CUDA 1131) are also processed on this PC and without any problems. I have no idea what could be causing it so I do not know how to fix it. Thanks in advance to anyone who can help me solve the problem. | |
| ID: 60425 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
i'm a bit surprised right now, i looked at the resend, it was successfully completed in just over 2 minutes, how come? the computer has more WUs that were successfully completed in such a short time. Am I doing something wrong? Did you figure out why? I couldn't find reply to this in the thread. I just started recently and half of my WUs are like that, while the others looks normal (other than the progress bar). Are these short ones legitimate results? https://www.gpugrid.net/result.php?resultid=33503009 https://www.gpugrid.net/result.php?resultid=33503008 https://www.gpugrid.net/result.php?resultid=33502957 https://www.gpugrid.net/result.php?resultid=33505285 ____________  | |
| ID: 60426 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
|
Is your computer connected to the Internet? Can you open https://github.com/raimis/AToM-OpenMM.git with your browser? I check a few results and next few lines are usually fetching from git repository, like this: 08:08:20 (12088): Library/usr/bin/tar.exe exited; CPU time 0.000000 08:08:20 (12088): wrapper: running C:/Windows/system32/cmd.exe (/c call run.bat) Running command git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git 'C:\ProgramData\BOINC\slots\13\tmp\pip-req-build-vp0jsx13' Running command git rev-parse -q --verify 'sha^d7931b9a6217232d481731f7589d64b100a514ac' Running command git fetch -q https://github.com/raimis/AToM-OpenMM.git d7931b9a6217232d481731f7589d64b100a514ac Running command git checkout -q d7931b9a6217232d481731f7589d64b100a514ac ____________ | |
| ID: 60427 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
i'm a bit surprised right now, i looked at the resend, it was successfully completed in just over 2 minutes, how come? the computer has more WUs that were successfully completed in such a short time. Am I doing something wrong? __________________ I have been having a sneaky suspicion about these two-minute affairs. Most of the job/ steps are done on some other computer then it errors. It restarts on another machine but from where it errored out. So, the bulk of the job gets done on one computer which gets no credit and completes on another in two minutes with all the credit. Nice na? :) ________ For example, we had an electric failure this morning and I suspended two tasks to put the laptops to sleep. Both ended with an error. The bulk of the job was done but someone else will complete it in two minutes. If on another machine it can do these acrobatics from the last good checkpoint then why is it not doing so on the original? As to the fairness of the affair, you decide. These tasks are not suspending or restarting as yet. | |
| ID: 60428 | Rating: 0 | rate:
| |
|
[FVG] pima1965 Send message Joined: 20 Jan 10 Posts: 4 Credit: 3,071,430,364 RAC: 349,993 Level Scientific publications | |
|
Hello and thanks for your reply. Yes, my PC is always connected to the internet, and I can correctly open https://github.com/raimis/AToM-OpenMM.git. Can you tell me what I have to do to solve my problem? Thanks again and best regards. | |
| ID: 60429 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
I have been having a sneaky suspicion about these two-minute affairs. Most of the job/ steps are done on some other computer then it errors. It restarts on another machine but from where it errored out. So, the bulk of the job gets done on one computer which gets no credit and completes on another in two minutes with all the credit. Nice na? I haven't heard any boinc project carrying over results from different hosts. If some hosts fail, others always start afresh. In addition, none of the WUs listed above had results from any other hosts. I suspect these are actually failures but somehow marked as success, but I can't confirm either way from the output. Credit is one thing, but these WUs also have a quorum of 1, meaning this is taken as the final result. If that's bogus, the project likely want to fix the bug, find these bogus results and rerun them somehow. ____________ | |
| ID: 60430 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
Hello and thanks for your reply. Yes, my PC is always connected to the internet, and I can correctly open https://github.com/raimis/AToM-OpenMM.git. Can you tell me what I have to do to solve my problem? Thanks again and best regards. 04:36:18 (31676): wrapper: running C:/Windows/system32/cmd.exe (/c call run.bat) 04:36:20 (31676): C:/Windows/system32/cmd.exe exited; CPU time 0.015625 04:36:20 (31676): app exit status: 0x1 Hmm, then I don't see anything else that could obvious go wrong. Your WUs basically failed at the "run.bat". Example extracted from the slot running the task on my host: https://pastebin.com/4nqK0egx. This script seems to be independent enough that you can try running on its own. Try this. 1) Get to your GPUGrid project folder inside BOINC data folder (default is %programdata%\BOINC\projects\www.gpugrid.net\) 2) Copy that windows_x86_64__cuda1121.zip.35a24fdec33997d4c4468c32b53b139c to a temporary folder and unzip it. 7-zip should be able to unzip it directly but at worst you rename it to .zip and then unzip it. 3) Copy the run.bat from the paste link into same folder, replace all `@echo` with `echo` and spray `timeout 5` everywhere. This would pause after each line and give you a chance to see the output. You might also want to change those "exit XX" to "echo something" so you see failure instead of exiting the shell immediately. Run the script from your temporary folder. (This is important. The script refers to %CD% so it's expected to run at the folder where all the unzipped files and run.bat reside.) This should tell you which step failed first, but how to fix that, well, depends on the failure. I expect you hit failure before `@echo Run AToM` line. PS: I am not very familiar with Windows, so there must be better ways to debug a batch file instead of 3). PS2: If you haven't already, reset the project first just to rule out the chance of some corrupted file. ____________ | |
| ID: 60431 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Hello and thanks for your reply. Yes, my PC is always connected to the internet, and I can correctly open https://github.com/raimis/AToM-OpenMM.git. Can you tell me what I have to do to solve my problem? Thanks again and best regards. ___________________ Here, solve it yourself. It is all gibberish to me. Marvels and Mysteries of ATM. task 33506305 I just come to check what my computers are doing. | |
| ID: 60432 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
Here, solve it yourself. It is all gibberish to me. Marvels and Mysteries of ATM. FYI, the reply you quoted wasn't replying to you. It was for pima (Message 60429). | |
| ID: 60433 | Rating: 0 | rate:
| |
|
[FVG] pima1965 Send message Joined: 20 Jan 10 Posts: 4 Credit: 3,071,430,364 RAC: 349,993 Level Scientific publications | |
|
Hello and thanks again. I have implemented everything you advised me; at the moment there are no ATMbeta tasks available, so I have no way of understanding if everything has led to any results. I will keep you informed. | |
| ID: 60434 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
FileNotFoundError: [Errno 2] No such file or directory: 'TYK2_m42_m54_0.xml' | |
| ID: 60435 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
When i did that i got this: | |
| ID: 60436 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
When i did that i got this: | |
| ID: 60437 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
FileNotFoundError: [Errno 2] No such file or directory: 'TYK2_m42_m54_0.xml' Crap, I forgot to clean those that didn't equilibrate succesfully here in local. Let me see if I can find the other few that crashed and cancel those WU. | |
| ID: 60438 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
"ValueError: Energy is NaN" is back quite often :-( Do these Energy is NaN come back really quickly? Run with similar names? Upon checking results I have seen that some runs have indeed crashed but not very often. | |
| ID: 60439 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
The difference between 0-5 and n-5 has been consistent throughout - there hasn't been a "fix and revert". Just new data runs starting from 0 again. So I'm usually trying to hit 350 samples which equivalates to a bit more than 60ns of sampling time. At the beginning I was sending the full run to a single volunteer but there were the size-issues and some people expressed that the samples were too long. I reduced the frame-saving frequency and started to divide these runs manually but this was too time-consuming and very hard to track. That was also causing issues with the progress bars. That's why later on it was implemented what we use now. Like in AceMD now we can chain these runs. Instead of sending the further steps manually it is done now automatically. This helped me divide the runs into smaller chunks, making runs smaller in size and faster to run. In theory this should have also fixed the issue with progress bars, since the cntl file also asks for +70 samples. But I guess that the first step of the runs show a proper progress bar but the following ones get stuck at 100% since the beginning? Since the control file reads +70 and the log file starts at 71. I'll pester the devs again to see if they can have a fix soon on it. About the recent errors. Some of them are on my end, I messed up a few times. We changed the preparation protocol and some running conditions for GPUGRID (as explained before) and sometimes a necessary tiny script was left there to run... I've taken the necessary measures to avoid this as much as possible. I hope we do not have an issue like before. Regarding the BACE files with very big size... Maybe I forgot to cancel some WUs? It was the first time I was doing this and the searchbar works very wonky. | |
| ID: 60440 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
Let me see if I can find the other few that crashed and cancel those WU. FileNotFoundError: https://www.gpugrid.net/result.php?resultid=33507881 Energy is NaN: https://www.gpugrid.net/result.php?resultid=33507902 https://www.gpugrid.net/result.php?resultid=33509252 ImportError: https://www.gpugrid.net/result.php?resultid=33504227 https://www.gpugrid.net/result.php?resultid=33503240 | |
| ID: 60441 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
Why does "python.exe -m pip install git+https://github.com/raimis/AToM-OpenMM.git@d7931b9a6217232d481731f7589d64b100a514ac" fail like this? | |
| ID: 60442 | Rating: 0 | rate:
| |
|
[FVG] pima1965 Send message Joined: 20 Jan 10 Posts: 4 Credit: 3,071,430,364 RAC: 349,993 Level Scientific publications | |
|
Good evening, due to my very poor IT skills, despite your precise instructions which I followed to the letter, I was not able to understand and solve the problem. Given that my other PCs, some with Windows 10 and some with Windows 11, do not have any kind of problem, I believe that the cause lies with this specific PC. For the moment I have disconnected this PC from the GPUGRID project and I have also uninstalled BOINC. When I have more time I will try again. Thanks again for your kind cooperation. | |
| ID: 60443 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
from openmm.openmm import * Ouch, sorry, I missed one step. Before you execute run.bat, you need to run this first inside the same folder: ".\python.exe bin/conda-unpack". Then run.bat should get you past the pip install command. Before doing that though, can I ask if you are into the same problem? I didn't find a similarly failed WU from your machines. The steps were only for pima1965's errors. If your WUs aren't running into setup failures but something else, there is no point of trying these steps at first place... PS: FWIW, the instructions I provided was simply trying to reproduce an environment based on projects\www.gpugrid.net\job.xml* without a running WU. Ultimately, if you can catch a running WU before it fails and gets cleaned up, you can copy its slot folder over to get a more accurate environment. (You can get the slot folder by checking the property of the task in UI.) | |
| ID: 60444 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I had 14 errors in a row last night, between about 18:30 and 19:30 UTC. All failed with a variant of Running command git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git /hdd/boinc-client/slots/5/tmp/pip-req-build-_q32nezm Is that something you can control? | |
| ID: 60445 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Let me see if I can find the other few that crashed and cancel those WU. Thanks for this, I will get a close look to these systems to see what could be the reason of the error. | |
| ID: 60446 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
I had 14 errors in a row last night, between about 18:30 and 19:30 UTC. All failed with a variant of It seems that this is a Github problem. It has been a bit unstable over the past few days. | |
| ID: 60447 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
4 tasks and 4 errors | |
| ID: 60451 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
Computer: DESKTOP-LFM92VN | |
| ID: 60456 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
What does run.log show? | |
| ID: 60460 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Could someone who has a stable power supply and no Al Nino events going on in their area disrupt the energy supply (South Asia, where I am is badly affected by squalls and rainfall) with a spare computer download it and install Python or Anaconda then check these WUs. (All my errors are now being caused by weather events and power failures). I allowed someone who is learning Python to use my computers and he installed these two. | |
| ID: 60462 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
I will have to look at the next one. | |
| ID: 60464 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
Yet another abort needed. What does run.log show? Setup environment D:\data\slots\0>set HOMEPATH=D:\data\slots\0 D:\data\slots\0>set PATH=D:\data\slots\0;D:\data\slots\0\Library\usr\bin;D:\data\slots\0\Library\bin;C:\Windows\system32;C:\Windows D:\data\slots\0>set PYTHONPATH=D:\data\slots\0\Lib\python3.9\site-packages D:\data\slots\0>set SYSTEMROOT=C:\Windows Create a temporary directory D:\data\slots\0>set TEMP=D:\data\slots\0\tmp D:\data\slots\0>mkdir D:\data\slots\0\tmp Install AToM D:\data\slots\0>set REPO_URL=git+https://github.com/raimis/AToM-OpenMM.git@d7931b9a6217232d481731f7589d64b100a514ac D:\data\slots\0>python.exe -m pip install git+https://github.com/raimis/AToM-OpenMM.git@d7931b9a6217232d481731f7589d64b100a514ac || exit 14 Collecting git+https://github.com/raimis/AToM-OpenMM.git@d7931b9a6217232d481731f7589d64b100a514ac Cloning https://github.com/raimis/AToM-OpenMM.git (to revision d7931b9a6217232d481731f7589d64b100a514ac) to d:\data\slots\0\tmp\pip-req-build-n4bnfm46 Resolved https://github.com/raimis/AToM-OpenMM.git to commit d7931b9a6217232d481731f7589d64b100a514ac Preparing metadata (setup.py): started Preparing metadata (setup.py): finished with status 'done' Building wheels for collected packages: async-re Building wheel for async-re (setup.py): started Building wheel for async-re (setup.py): finished with status 'done' Created wheel for async-re: filename=async_re-3.3.0-py3-none-any.whl size=40735 sha256=b78cd7a2db0c0a4584d16c9a7967a2bdafe4f91754d0514cf1d4be7fd9e7038f Stored in directory: c:\users\greg\appdata\local\pip\cache\wheels\e3\94\02\5d2f795e8088e5cda09e48b0a167d6325c316862c02fa11467 Successfully built async-re Installing collected packages: async-re Successfully installed async-re-3.3.0 D:\data\slots\0>python.exe -m pip list Package Version ------------ ------- async-re 3.3.0 atmmetaforce 0.3 configobj 5.0.8 numpy 1.24.2 OpenMM 8.0.0 pip 23.0.1 setuptools 67.6.0 six 1.16.0 wheel 0.40.0 Configure AToM D:\data\slots\0>echo localhost,0:0,1,CUDA,,D:\data\slots\0\tmp 1>nodefile Extract restart D:\data\slots\0>tar.exe xjvf restart.tar.bz2 || true r0/p38_m2z_maa_ckpt.xml r1/p38_m2z_maa_ckpt.xml r10/p38_m2z_maa_ckpt.xml r11/p38_m2z_maa_ckpt.xml r12/p38_m2z_maa_ckpt.xml r13/p38_m2z_maa_ckpt.xml r14/p38_m2z_maa_ckpt.xml r15/p38_m2z_maa_ckpt.xml r16/p38_m2z_maa_ckpt.xml r17/p38_m2z_maa_ckpt.xml r18/p38_m2z_maa_ckpt.xml r19/p38_m2z_maa_ckpt.xml r2/p38_m2z_maa_ckpt.xml r20/p38_m2z_maa_ckpt.xml r21/p38_m2z_maa_ckpt.xml r3/p38_m2z_maa_ckpt.xml r4/p38_m2z_maa_ckpt.xml r5/p38_m2z_maa_ckpt.xml r6/p38_m2z_maa_ckpt.xml r7/p38_m2z_maa_ckpt.xml r8/p38_m2z_maa_ckpt.xml r9/p38_m2z_maa_ckpt.xml Run AToM D:\data\slots\0>set CONFIG_FILE=p38_m2z_maa_asyncre.cntl D:\data\slots\0>python.exe Scripts\rbfe_explicit_sync.py p38_m2z_maa_asyncre.cntl || exit 22 2023-05-21 12:44:43 - INFO - sync_re - Configuration: 2023-05-21 12:44:43 - INFO - sync_re - JOB_TRANSPORT: LOCAL_OPENMM 2023-05-21 12:44:43 - INFO - sync_re - BASENAME: p38_m2z_maa 2023-05-21 12:44:43 - INFO - sync_re - RE_SETUP: YES 2023-05-21 12:44:43 - INFO - sync_re - TEMPERATURES: 300 2023-05-21 12:44:43 - INFO - sync_re - LAMBDAS: 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40, 0.45, 0.50, 0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95, 1.00 2023-05-21 12:44:43 - INFO - sync_re - DIRECTION: 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 2023-05-21 12:44:43 - INFO - sync_re - INTERMEDIATE: 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 2023-05-21 12:44:43 - INFO - sync_re - LAMBDA1: 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.10, 0.20, 0.30, 0.40, 0.50, 0.50, 0.40, 0.30, 0.20, 0.10, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00 2023-05-21 12:44:43 - INFO - sync_re - LAMBDA2: 0.00, 0.10, 0.20, 0.30, 0.40, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.40, 0.30, 0.20, 0.10, 0.00 2023-05-21 12:44:43 - INFO - sync_re - ALPHA: 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10, 0.10 2023-05-21 12:44:43 - INFO - sync_re - U0: 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110., 110. 2023-05-21 12:44:43 - INFO - sync_re - W0COEFF: 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 2023-05-21 12:44:43 - INFO - sync_re - DISPLACEMENT: 22.0, 22.0, 22.0 2023-05-21 12:44:43 - INFO - sync_re - WALL_TIME: 9999 2023-05-21 12:44:43 - INFO - sync_re - CYCLE_TIME: 60 2023-05-21 12:44:43 - INFO - sync_re - CHECKPOINT_TIME: 300 2023-05-21 12:44:43 - INFO - sync_re - NODEFILE: nodefile 2023-05-21 12:44:43 - INFO - sync_re - SUBJOBS_BUFFER_SIZE: 0 2023-05-21 12:44:43 - INFO - sync_re - PRODUCTION_STEPS: 2000 2023-05-21 12:44:43 - INFO - sync_re - PRNT_FREQUENCY: 2000 2023-05-21 12:44:43 - INFO - sync_re - TRJ_FREQUENCY: 40000 2023-05-21 12:44:43 - INFO - sync_re - LIGAND1_ATOMS: ['5596', '5597', '5598', '5599', '5600', '5601', '5602', '5603', '5604', '5605', '5606', '5607', '5608', '5609', '5610', '5611', '5612', '5613', '5614', '5615', '5616', '5617', '5618', '5619', '5620', '5621', '5622', '5623', '5624', '5625', '5626', '5627', '5628', '5629', '5630', '5631', '5632', '5633', '5634', '5635', '5636', '5637', '5638', '5639', '5640'] 2023-05-21 12:44:43 - INFO - sync_re - LIGAND2_ATOMS: ['5641', '5642', '5643', '5644', '5645', '5646', '5647', '5648', '5649', '5650', '5651', '5652', '5653', '5654', '5655', '5656', '5657', '5658', '5659', '5660', '5661', '5662', '5663', '5664', '5665', '5666', '5667', '5668', '5669', '5670', '5671', '5672', '5673', '5674', '5675', '5676', '5677', '5678', '5679', '5680', '5681', '5682', '5683'] 2023-05-21 12:44:43 - INFO - sync_re - LIGAND1_CM_ATOMS: 5601 2023-05-21 12:44:43 - INFO - sync_re - LIGAND2_CM_ATOMS: 5646 2023-05-21 12:44:43 - INFO - sync_re - RCPT_CM_ATOMS: ['460', '483', '494', '501', '550', '745', '755', '771', '1178', '1337', '1363', '1654', '1673', '1689', '1703', '1720', '1739', '1756', '1763', '1773', '2532', '2685'] 2023-05-21 12:44:43 - INFO - sync_re - CM_KF: 25.00 2023-05-21 12:44:43 - INFO - sync_re - CM_TOL: 10 2023-05-21 12:44:43 - INFO - sync_re - POS_RESTRAINED_ATOMS: ['4', '19', '51', '57', '71', '91', '112', '136', '153', '168', '187', '201', '223', '237', '256', '280', '295', '319', '325', '340', '364', '385', '402', '416', '435', '454', '460', '476', '483', '494', '501', '511', '532', '539', '550', '566', '577', '587', '597', '617', '629', '643', '665', '679', '686', '705', '729', '745', '755', '771', '793', '815', '834', '845', '877', '883', '903', '920', '931', '950', '969', '986', '996', '1018', '1042', '1056', '1077', '1101', '1116', '1135', '1159', '1178', '1197', '1219', '1236', '1253', '1275', '1292', '1307', '1321', '1337', '1356', '1363', '1382', '1401', '1413', '1429', '1449', '1471', '1477', '1487', '1511', '1522', '1541', '1556', '1571', '1591', '1605', '1617', '1633', '1654', '1673', '1689', '1703', '1720', '1739', '1756', '1763', '1773', '1785', '1804', '1818', '1832', '1851', '1867', '1889', '1900', '1917', '1939', '1958', '1972', '1984', '1996', '2013', '2029', '2046', '2066', '2085', '2104', '2125', '2142', '2161', '2180', '2204', '2211', '2230', '2252', '2273', '2292', '2309', '2320', '2330', '2342', '2361', '2380', '2397', '2421', '2433', '2452', '2482', '2488', '2499', '2513', '2532', '2542', '2558', '2572', '2587', '2599', '2610', '2625', '2644', '2666', '2685', '2704', '2716', '2736', '2743', '2765', '2782', '2796', '2808', '2820', '2835', '2852', '2866', '2873', '2894', '2910', '2920', '2934', '2958', '2982', '3003', '3027', '3045', '3051', '3066', '3085', '3102', '3121', '3135', '3159', '3176', '3193', '3214', '3228', '3245', '3259', '3275', '3287', '3306', '3330', '3341', '3357', '3364', '3375', '3394', '3411', '3421', '3436', '3455', '3474', '3488', '3495', '3519', '3533', '3552', '3580', '3586', '3593', '3607', '3619', '3636', '3655', '3667', '3684', '3703', '3725', '3744', '3763', '3782', '3806', '3825', '3841', '3848', '3870', '3876', '3883', '3893', '3908', '3927', '3946', '3968', '3990', '4009', '4020', '4031', '4046', '4057', '4067', '4091', '4105', '4126', '4145', '4162', '4173', '4192', '4206', '4223', '4248', '4254', '4276', '4293', '4307', '4327', '4337', '4351', '4367', '4387', '4406', '4413', '4423', '4445', '4451', '4470', '4480', '4496', '4508', '4527', '4546', '4561', '4583', '4600', '4619', '4635', '4654', '4666', '4677', '4689', '4711', '4735', '4754', '4768', '4778', '4788', '4805', '4815', '4834', '4844', '4861', '4871', '4892', '4912', '4922', '4939', '4960', '4977', '4997', '5003', '5015', '5027', '5050', '5056', '5072', '5082', '5102', '5108', '5129', '5141', '5158', '5169', '5189', '5204', '5215', '5239', '5251', '5270', '5289', '5308', '5320', '5335', '5359', '5381', '5392', '5411', '5425', '5446', '5458', '5473', '5489', '5508', '5519', '5539', '5563', '5577', '5591'] 2023-05-21 12:44:43 - INFO - sync_re - POSRE_FORCE_CONSTANT: 25.0 2023-05-21 12:44:43 - INFO - sync_re - POSRE_TOLERANCE: 1.5 2023-05-21 12:44:43 - INFO - sync_re - ALIGN_LIGAND1_REF_ATOMS: ['5', '1', '20'] 2023-05-21 12:44:43 - INFO - sync_re - ALIGN_LIGAND2_REF_ATOMS: ['5', '1', '20'] 2023-05-21 12:44:43 - INFO - sync_re - ALIGN_KF_SEP: 2.5 2023-05-21 12:44:43 - INFO - sync_re - ALIGN_K_THETA: 25.0 2023-05-21 12:44:43 - INFO - sync_re - ALIGN_K_PSI: 25.0 2023-05-21 12:44:43 - INFO - sync_re - UMAX: 200.00 2023-05-21 12:44:43 - INFO - sync_re - ACORE: 0.062500 2023-05-21 12:44:43 - INFO - sync_re - UBCORE: 100.0 2023-05-21 12:44:43 - INFO - sync_re - FRICTION_COEFF: 0.100000 2023-05-21 12:44:43 - INFO - sync_re - TIME_STEP: 0.004 2023-05-21 12:44:43 - INFO - sync_re - OPENMM_PLATFORM: CUDA 2023-05-21 12:44:43 - INFO - sync_re - VERBOSE: no 2023-05-21 12:44:43 - INFO - sync_re - HMASS: 1.5 2023-05-21 12:44:43 - INFO - sync_re - MAX_SAMPLES: +70 2023-05-21 12:44:43 - INFO - sync_re - State parameters 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.0, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.0, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.05, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.1, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.1, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.2, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.15, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.3, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.2, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.4, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.25, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.3, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.1, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.35, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.2, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.4, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.3, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.45, 'atmdirection': 1.0, 'atmintermediate': 0.0, 'lambda1': 0.4, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.5, 'atmdirection': 1.0, 'atmintermediate': 1.0, 'lambda1': 0.5, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=1.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.5, 'atmdirection': -1.0, 'atmintermediate': 1.0, 'lambda1': 0.5, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=1.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.55, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.4, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.6, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.3, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.65, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.2, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.7, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.1, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.75, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.5, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.8, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.4, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.85, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.3, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.9, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.2, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 0.95, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.1, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - State: {'lambda': 1.0, 'atmdirection': -1.0, 'atmintermediate': 0.0, 'lambda1': 0.0, 'lambda2': 0.0, 'alpha': Quantity(value=0.1, unit=mole/kilocalorie), 'u0': Quantity(value=110.0, unit=kilocalorie/mole), 'w0': Quantity(value=0.0, unit=kilocalorie/mole), 'temperature': Quantity(value=300.0, unit=kelvin)} 2023-05-21 12:44:43 - INFO - sync_re - Started: ATM setup 2023-05-21 12:44:43 - INFO - sync_re - Started: create system warning: AddRestraintForce() is deprecated. Use addVsiteRestraintForceCMCM() warning: AddRestraintForce() is deprecated. Use addVsiteRestraintForceCMCM() 2023-05-21 12:44:46 - INFO - sync_re - Running with a 4.000000 fs time-step with bonded forces integrated 4 times per time-step 2023-05-21 12:44:46 - INFO - sync_re - Finished: create system (duration: 3.515999999999849 s) 2023-05-21 12:44:46 - INFO - sync_re - Started: create worker 2023-05-21 12:44:46 - INFO - sync_re - Device: CUDA 0 2023-05-21 12:45:24 - INFO - sync_re - Finished: create worker (duration: 37.702999999999975 s) 2023-05-21 12:45:24 - INFO - sync_re - Started: create replicas 2023-05-21 12:45:24 - INFO - sync_re - Loading checkpointfile r0/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:27 - INFO - sync_re - Loading checkpointfile r1/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:29 - INFO - sync_re - Loading checkpointfile r2/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:32 - INFO - sync_re - Loading checkpointfile r3/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:34 - INFO - sync_re - Loading checkpointfile r4/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:37 - INFO - sync_re - Loading checkpointfile r5/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:39 - INFO - sync_re - Loading checkpointfile r6/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:42 - INFO - sync_re - Loading checkpointfile r7/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:44 - INFO - sync_re - Loading checkpointfile r8/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:47 - INFO - sync_re - Loading checkpointfile r9/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:49 - INFO - sync_re - Loading checkpointfile r10/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:52 - INFO - sync_re - Loading checkpointfile r11/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:54 - INFO - sync_re - Loading checkpointfile r12/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:57 - INFO - sync_re - Loading checkpointfile r13/p38_m2z_maa_ckpt.xml 2023-05-21 12:45:59 - INFO - sync_re - Loading checkpointfile r14/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:02 - INFO - sync_re - Loading checkpointfile r15/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:04 - INFO - sync_re - Loading checkpointfile r16/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:07 - INFO - sync_re - Loading checkpointfile r17/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:09 - INFO - sync_re - Loading checkpointfile r18/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:12 - INFO - sync_re - Loading checkpointfile r19/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:14 - INFO - sync_re - Loading checkpointfile r20/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:17 - INFO - sync_re - Loading checkpointfile r21/p38_m2z_maa_ckpt.xml 2023-05-21 12:46:19 - INFO - sync_re - Replica 0: cycle 211, state 5 2023-05-21 12:46:19 - INFO - sync_re - Replica 1: cycle 211, state 2 2023-05-21 12:46:19 - INFO - sync_re - Replica 2: cycle 211, state 3 2023-05-21 12:46:19 - INFO - sync_re - Replica 3: cycle 211, state 11 2023-05-21 12:46:19 - INFO - sync_re - Replica 4: cycle 211, state 1 2023-05-21 12:46:19 - INFO - sync_re - Replica 5: cycle 211, state 6 2023-05-21 12:46:19 - INFO - sync_re - Replica 6: cycle 211, state 1 2023-05-21 12:46:19 - INFO - sync_re - Replica 7: cycle 211, state 10 2023-05-21 12:46:19 - INFO - sync_re - Replica 8: cycle 211, state 4 2023-05-21 12:46:19 - INFO - sync_re - Replica 9: cycle 211, state 8 2023-05-21 12:46:19 - INFO - sync_re - Replica 10: cycle 211, state 7 2023-05-21 12:46:19 - INFO - sync_re - Replica 11: cycle 211, state 20 2023-05-21 12:46:19 - INFO - sync_re - Replica 12: cycle 211, state 12 2023-05-21 12:46:19 - INFO - sync_re - Replica 13: cycle 211, state 14 2023-05-21 12:46:19 - INFO - sync_re - Replica 14: cycle 211, state 9 2023-05-21 12:46:19 - INFO - sync_re - Replica 15: cycle 211, state 13 2023-05-21 12:46:19 - INFO - sync_re - Replica 16: cycle 211, state 19 2023-05-21 12:46:19 - INFO - sync_re - Replica 17: cycle 211, state 15 2023-05-21 12:46:19 - INFO - sync_re - Replica 18: cycle 211, state 17 2023-05-21 12:46:19 - INFO - sync_re - Replica 19: cycle 211, state 16 2023-05-21 12:46:19 - INFO - sync_re - Replica 20: cycle 211, state 18 2023-05-21 12:46:19 - INFO - sync_re - Replica 21: cycle 211, state 21 2023-05-21 12:46:19 - INFO - sync_re - Finished: create replicas (duration: 55.406000000000176 s) 2023-05-21 12:46:19 - INFO - sync_re - Started: update replicas 2023-05-21 12:46:28 - INFO - sync_re - Finished: update replicas (duration: 9.1099999999999 s) 2023-05-21 12:46:28 - INFO - sync_re - Finished: ATM setup (duration: 105.7349999999999 s) 2023-05-21 12:46:28 - INFO - sync_re - Started: ATM simulations 2023-05-21 12:46:28 - INFO - sync_re - Additional number of samples: 70 2023-05-21 12:46:28 - INFO - sync_re - Started: sample 211 2023-05-21 12:46:28 - INFO - sync_re - Started: sample 211, replica 0 2023-05-21 12:47:05 - INFO - sync_re - Finished: sample 211, replica 0 (duration: 36.125 s) 2023-05-21 12:47:05 - INFO - sync_re - Started: sample 211, replica 1 2023-05-21 12:47:35 - INFO - sync_re - Finished: sample 211, replica 1 (duration: 30.8900000000001 s) 2023-05-21 12:47:35 - INFO - sync_re - Started: sample 211, replica 2 2023-05-21 12:48:07 - INFO - sync_re - Finished: sample 211, replica 2 (duration: 31.9849999999999 s) 2023-05-21 12:48:07 - INFO - sync_re - Started: sample 211, replica 3 2023-05-21 12:48:38 - INFO - sync_re - Finished: sample 211, replica 3 (duration: 30.54600000000005 s) 2023-05-21 12:48:38 - INFO - sync_re - Started: sample 211, replica 4 2023-05-21 12:49:09 - INFO - sync_re - Finished: sample 211, replica 4 (duration: 31.297000000000025 s) 2023-05-21 12:49:09 - INFO - sync_re - Started: sample 211, replica 5 2023-05-21 12:49:41 - INFO - sync_re - Finished: sample 211, replica 5 (duration: 31.375 s) 2023-05-21 12:49:41 - INFO - sync_re - Started: sample 211, replica 6 2023-05-21 12:50:11 - INFO - sync_re - Finished: sample 211, replica 6 (duration: 30.672000000000025 s) 2023-05-21 12:50:11 - INFO - sync_re - Started: sample 211, replica 7 2023-05-21 12:50:43 - INFO - sync_re - Finished: sample 211, replica 7 (duration: 31.6099999999999 s) 2023-05-21 12:50:43 - INFO - sync_re - Started: sample 211, replica 8 2023-05-21 12:51:14 - INFO - sync_re - Finished: sample 211, replica 8 (duration: 30.843000000000075 s) 2023-05-21 12:51:14 - INFO - sync_re - Started: sample 211, replica 9 2023-05-21 12:51:42 - INFO - sync_re - Finished: sample 211, replica 9 (duration: 28.672000000000025 s) 2023-05-21 12:51:42 - INFO - sync_re - Started: sample 211, replica 10 2023-05-21 12:52:13 - INFO - sync_re - Finished: sample 211, replica 10 (duration: 30.5 s) 2023-05-21 12:52:13 - INFO - sync_re - Started: sample 211, replica 11 2023-05-21 12:52:43 - INFO - sync_re - Finished: sample 211, replica 11 (duration: 30.312999999999874 s) 2023-05-21 12:52:43 - INFO - sync_re - Started: sample 211, replica 12 2023-05-21 12:53:15 - INFO - sync_re - Finished: sample 211, replica 12 (duration: 31.797000000000025 s) 2023-05-21 12:53:15 - INFO - sync_re - Started: sample 211, replica 13 2023-05-21 12:53:48 - INFO - sync_re - Finished: sample 211, replica 13 (duration: 32.5 s) 2023-05-21 12:53:48 - INFO - sync_re - Started: sample 211, replica 14 2023-05-21 12:54:20 - INFO - sync_re - Finished: sample 211, replica 14 (duration: 32.53099999999995 s) 2023-05-21 12:54:20 - INFO - sync_re - Started: sample 211, replica 15 2023-05-21 12:54:52 - INFO - sync_re - Finished: sample 211, replica 15 (duration: 32.34400000000005 s) 2023-05-21 12:54:52 - INFO - sync_re - Started: sample 211, replica 16 2023-05-21 12:55:24 - INFO - sync_re - Finished: sample 211, replica 16 (duration: 31.75 s) 2023-05-21 12:55:24 - INFO - sync_re - Started: sample 211, replica 17 2023-05-21 12:55:56 - INFO - sync_re - Finished: sample 211, replica 17 (duration: 31.875 s) 2023-05-21 12:55:56 - INFO - sync_re - Started: sample 211, replica 18 2023-05-21 12:56:29 - INFO - sync_re - Finished: sample 211, replica 18 (duration: 32.4849999999999 s) 2023-05-21 12:56:29 - INFO - sync_re - Started: sample 211, replica 19 2023-05-21 12:56:59 - INFO - sync_re - Finished: sample 211, replica 19 (duration: 30.077999999999975 s) 2023-05-21 12:56:59 - INFO - sync_re - Started: sample 211, replica 20 2023-05-21 12:57:30 - INFO - sync_re - Finished: sample 211, replica 20 (duration: 31.2650000000001 s) 2023-05-21 12:57:30 - INFO - sync_re - Started: sample 211, replica 21 2023-05-21 12:58:00 - INFO - sync_re - Finished: sample 211, replica 21 (duration: 30.593999999999824 s) 2023-05-21 12:58:00 - INFO - sync_re - Started: exchange replicas 2023-05-21 12:58:00 - INFO - sync_re - Replica 18: 17 --> 18 2023-05-21 12:58:00 - INFO - sync_re - Replica 20: 18 --> 17 2023-05-21 12:58:00 - INFO - sync_re - Finished: exchange replicas (duration: 0.047000000000025466 s) 2023-05-21 12:58:00 - INFO - sync_re - Started: update replicas 2023-05-21 12:58:09 - INFO - sync_re - Finished: update replicas (duration: 8.812000000000126 s) 2023-05-21 12:58:09 - INFO - sync_re - Started: write replicas samples and trajectories 2023-05-21 12:58:09 - INFO - sync_re - Finished: write replicas samples and trajectories (duration: 0.015999999999849024 s) 2023-05-21 12:58:09 - INFO - sync_re - Started: checkpointing 2023-05-21 12:58:59 - INFO - sync_re - Finished: checkpointing (duration: 50.031000000000176 s) 2023-05-21 12:58:59 - INFO - sync_re - Finished: sample 211 (duration: 750.9680000000001 s) 2023-05-21 12:58:59 - INFO - sync_re - Started: sample 212 2023-05-21 12:58:59 - INFO - sync_re - Started: sample 212, replica 0 2023-05-21 12:59:30 - INFO - sync_re - Finished: sample 212, replica 0 (duration: 30.687999999999874 s) 2023-05-21 12:59:30 - INFO - sync_re - Started: sample 212, replica 1 2023-05-21 13:00:00 - INFO - sync_re - Finished: sample 212, replica 1 (duration: 30.25 s) 2023-05-21 13:00:00 - INFO - sync_re - Started: sample 212, replica 2 2023-05-21 13:00:31 - INFO - sync_re - Finished: sample 212, replica 2 (duration: 30.797000000000025 s) 2023-05-21 13:00:31 - INFO - sync_re - Started: sample 212, replica 3 2023-05-21 13:01:02 - INFO - sync_re - Finished: sample 212, replica 3 (duration: 30.467999999999847 s) 2023-05-21 13:01:02 - INFO - sync_re - Started: sample 212, replica 4 2023-05-21 13:01:31 - INFO - sync_re - Finished: sample 212, replica 4 (duration: 29.71900000000005 s) 2023-05-21 13:01:31 - INFO - sync_re - Started: sample 212, replica 5 2023-05-21 13:02:02 - INFO - sync_re - Finished: sample 212, replica 5 (duration: 30.90599999999995 s) 2023-05-21 13:02:02 - INFO - sync_re - Started: sample 212, replica 6 2023-05-21 13:02:32 - INFO - sync_re - Finished: sample 212, replica 6 (duration: 29.96900000000005 s) 2023-05-21 13:02:32 - INFO - sync_re - Started: sample 212, replica 7 2023-05-21 13:03:03 - INFO - sync_re - Finished: sample 212, replica 7 (duration: 30.391000000000076 s) 2023-05-21 13:03:03 - INFO - sync_re - Started: sample 212, replica 8 2023-05-21 13:03:33 - INFO - sync_re - Finished: sample 212, replica 8 (duration: 30.34400000000005 s) 2023-05-21 13:03:33 - INFO - sync_re - Started: sample 212, replica 9 2023-05-21 13:04:04 - INFO - sync_re - Finished: sample 212, replica 9 (duration: 30.79599999999982 s) 2023-05-21 13:04:04 - INFO - sync_re - Started: sample 212, replica 10 2023-05-21 13:04:34 - INFO - sync_re - Finished: sample 212, replica 10 (duration: 30.375 s) 2023-05-21 13:04:34 - INFO - sync_re - Started: sample 212, replica 11 2023-05-21 13:05:04 - INFO - sync_re - Finished: sample 212, replica 11 (duration: 30.063000000000102 s) 2023-05-21 13:05:04 - INFO - sync_re - Started: sample 212, replica 12 2023-05-21 13:05:34 - INFO - sync_re - Finished: sample 212, replica 12 (duration: 29.827999999999975 s) 2023-05-21 13:05:34 - INFO - sync_re - Started: sample 212, replica 13 2023-05-21 13:06:05 - INFO - sync_re - Finished: sample 212, replica 13 (duration: 30.952999999999975 s) 2023-05-21 13:06:05 - INFO - sync_re - Started: sample 212, replica 14 2023-05-21 13:06:35 - INFO - sync_re - Finished: sample 212, replica 14 (duration: 30.264999999999873 s) 2023-05-21 13:06:35 - INFO - sync_re - Started: sample 212, replica 15 2023-05-21 13:07:04 - INFO - sync_re - Finished: sample 212, replica 15 (duration: 28.563000000000102 s) 2023-05-21 13:07:04 - INFO - sync_re - Started: sample 212, replica 16 2023-05-21 13:07:16 - INFO - sync_re - Finished: sample 212, replica 16 (duration: 12.0 s) 2023-05-21 13:07:16 - INFO - sync_re - Started: sample 212, replica 17 2023-05-21 13:07:27 - INFO - sync_re - Finished: sample 212, replica 17 (duration: 11.530999999999949 s) 2023-05-21 13:07:27 - INFO - sync_re - Started: sample 212, replica 18 2023-05-21 13:07:39 - INFO - sync_re - Finished: sample 212, replica 18 (duration: 11.938000000000102 s) 2023-05-21 13:07:39 - INFO - sync_re - Started: sample 212, replica 19 2023-05-21 13:07:51 - INFO - sync_re - Finished: sample 212, replica 19 (duration: 11.5 s) 2023-05-21 13:07:51 - INFO - sync_re - Started: sample 212, replica 20 2023-05-21 13:08:03 - INFO - sync_re - Finished: sample 212, replica 20 (duration: 11.967999999999847 s) 2023-05-21 13:08:03 - INFO - sync_re - Started: sample 212, replica 21 2023-05-21 13:08:14 - INFO - sync_re - Finished: sample 212, replica 21 (duration: 11.672000000000025 s) 2023-05-21 13:08:14 - INFO - sync_re - Started: exchange replicas 2023-05-21 13:08:14 - INFO - sync_re - Replica 4: 1 --> 1 2023-05-21 13:08:14 - INFO - sync_re - Replica 6: 1 --> 1 2023-05-21 13:08:14 - INFO - sync_re - Replica 7: 10 --> 11 2023-05-21 13:08:14 - INFO - sync_re - Replica 3: 11 --> 10 2023-05-21 13:08:14 - INFO - sync_re - Finished: exchange replicas (duration: 0.06300000000010186 s) 2023-05-21 13:08:14 - INFO - sync_re - Started: update replicas 2023-05-21 13:08:23 - INFO - sync_re - Finished: update replicas (duration: 8.827999999999975 s) 2023-05-21 13:08:23 - INFO - sync_re - Started: write replicas samples and trajectories 2023-05-21 13:08:23 - INFO - sync_re - Finished: write replicas samples and trajectories (duration: 0.0 s) 2023-05-21 13:08:23 - INFO - sync_re - Started: checkpointing 2023-05-21 13:09:12 - INFO - sync_re - Finished: checkpointing (duration: 49.266000000000076 s) 2023-05-21 13:09:13 - INFO - sync_re - Finished: sample 212 (duration: 613.1569999999999 s) 2023-05-21 13:09:13 - INFO - sync_re - Started: sample 213 2023-05-21 13:09:13 - INFO - sync_re - Started: sample 213, replica 0 2023-05-21 13:09:59 - INFO - sync_re - Finished: sample 213, replica 0 (duration: 46.4369999999999 s) 2023-05-21 13:09:59 - INFO - sync_re - Started: sample 213, replica 1 2023-05-21 13:10:45 - INFO - sync_re - Finished: sample 213, replica 1 (duration: 45.733999999999924 s) 2023-05-21 13:10:45 - INFO - sync_re - Started: sample 213, replica 2 2023-05-21 13:11:33 - INFO - sync_re - Finished: sample 213, replica 2 (duration: 48.28200000000015 s) 2023-05-21 13:11:33 - INFO - sync_re - Started: sample 213, replica 3 2023-05-21 13:12:24 - INFO - sync_re - Finished: sample 213, replica 3 (duration: 51.3119999999999 s) 2023-05-21 13:12:24 - INFO - sync_re - Started: sample 213, replica 4 2023-05-21 13:13:16 - INFO - sync_re - Finished: sample 213, replica 4 (duration: 51.922000000000025 s) 2023-05-21 13:13:16 - INFO - sync_re - Started: sample 213, replica 5 2023-05-21 13:14:08 - INFO - sync_re - Finished: sample 213, replica 5 (duration: 51.375 s) 2023-05-21 13:14:08 - INFO - sync_re - Started: sample 213, replica 6 2023-05-21 13:14:59 - INFO - sync_re - Finished: sample 213, replica 6 (duration: 51.53099999999995 s) 2023-05-21 13:14:59 - INFO - sync_re - Started: sample 213, replica 7 2023-05-21 13:15:51 - INFO - sync_re - Finished: sample 213, replica 7 (duration: 51.8130000000001 s) 2023-05-21 13:15:51 - INFO - sync_re - Started: sample 213, replica 8 2023-05-21 13:16:42 - INFO - sync_re - Finished: sample 213, replica 8 (duration: 51.0619999999999 s) 2023-05-21 13:16:42 - INFO - sync_re - Started: sample 213, replica 9 2023-05-21 13:17:34 - INFO - sync_re - Finished: sample 213, replica 9 (duration: 51.98500000000013 s) 2023-05-21 13:17:34 - INFO - sync_re - Started: sample 213, replica 10 2023-05-21 13:18:26 - INFO - sync_re - Finished: sample 213, replica 10 (duration: 52.0 s) 2023-05-21 13:18:26 - INFO - sync_re - Started: sample 213, replica 11 2023-05-21 13:19:18 - INFO - sync_re - Finished: sample 213, replica 11 (duration: 52.28099999999995 s) 2023-05-21 13:19:18 - INFO - sync_re - Started: sample 213, replica 12 2023-05-21 13:20:10 - INFO - sync_re - Finished: sample 213, replica 12 (duration: 51.266000000000076 s) 2023-05-21 13:20:10 - INFO - sync_re - Started: sample 213, replica 13 2023-05-21 13:21:03 - INFO - sync_re - Finished: sample 213, replica 13 (duration: 53.233999999999924 s) 2023-05-21 13:21:03 - INFO - sync_re - Started: sample 213, replica 14 2023-05-21 13:21:55 - INFO - sync_re - Finished: sample 213, replica 14 (duration: 52.03099999999995 s) 2023-05-21 13:21:55 - INFO - sync_re - Started: sample 213, replica 15 2023-05-21 13:22:49 - INFO - sync_re - Finished: sample 213, replica 15 (duration: 53.75 s) 2023-05-21 13:22:49 - INFO - sync_re - Started: sample 213, replica 16 2023-05-21 13:23:42 - INFO - sync_re - Finished: sample 213, replica 16 (duration: 53.077999999999975 s) 2023-05-21 13:23:42 - INFO - sync_re - Started: sample 213, replica 17 2023-05-21 13:24:34 - INFO - sync_re - Finished: sample 213, replica 17 (duration: 52.327999999999975 s) 2023-05-21 13:24:34 - INFO - sync_re - Started: sample 213, replica 18 2023-05-21 13:25:27 - INFO - sync_re - Finished: sample 213, replica 18 (duration: 52.82900000000018 s) 2023-05-21 13:25:27 - INFO - sync_re - Started: sample 213, replica 19 2023-05-21 13:26:20 - INFO - sync_re - Finished: sample 213, replica 19 (duration: 52.92099999999982 s) 2023-05-21 13:26:20 - INFO - sync_re - Started: sample 213, replica 20 2023-05-21 13:27:13 - INFO - sync_re - Finished: sample 213, replica 20 (duration: 53.40700000000015 s) 2023-05-21 13:27:13 - INFO - sync_re - Started: sample 213, replica 21 2023-05-21 13:28:05 - INFO - sync_re - Finished: sample 213, replica 21 (duration: 52.28099999999995 s) 2023-05-21 13:28:05 - INFO - sync_re - Started: exchange replicas 2023-05-21 13:28:05 - INFO - sync_re - Finished: exchange replicas (duration: 0.047000000000025466 s) 2023-05-21 13:28:05 - INFO - sync_re - Started: update replicas 2023-05-21 13:28:14 - INFO - sync_re - Finished: update replicas (duration: 9.030999999999949 s) 2023-05-21 13:28:14 - INFO - sync_re - Started: write replicas samples and trajectories 2023-05-21 13:28:14 - INFO - sync_re - Finished: write replicas samples and trajectories (duration: 0.0 s) 2023-05-21 13:28:14 - INFO - sync_re - Started: checkpointing 2023-05-21 13:29:04 - INFO - sync_re - Finished: checkpointing (duration: 50.016000000000076 s) 2023-05-21 13:29:04 - INFO - sync_re - Finished: sample 213 (duration: 1191.953 s) 2023-05-21 13:29:04 - INFO - sync_re - Started: sample 214 2023-05-21 13:29:04 - INFO - sync_re - Started: sample 214, replica 0 2023-05-21 13:29:58 - INFO - sync_re - Finished: sample 214, replica 0 (duration: 53.28099999999995 s) 2023-05-21 13:29:58 - INFO - sync_re - Started: sample 214, replica 1 2023-05-21 13:30:50 - INFO - sync_re - Finished: sample 214, replica 1 (duration: 52.483999999999924 s) 2023-05-21 13:30:50 - INFO - sync_re - Started: sample 214, replica 2 2023-05-21 13:31:43 - INFO - sync_re - Finished: sample 214, replica 2 (duration: 53.172000000000025 s) 2023-05-21 13:31:43 - INFO - sync_re - Started: sample 214, replica 3 2023-05-21 13:32:37 - INFO - sync_re - Finished: sample 214, replica 3 (duration: 53.141000000000076 s) 2023-05-21 13:32:37 - INFO - sync_re - Started: sample 214, replica 4 2023-05-21 13:33:30 - INFO - sync_re - Finished: sample 214, replica 4 (duration: 53.63999999999987 s) 2023-05-21 13:33:30 - INFO - sync_re - Started: sample 214, replica 5 2023-05-21 13:34:22 - INFO - sync_re - Finished: sample 214, replica 5 (duration: 51.98500000000013 s) 2023-05-21 13:34:22 - INFO - sync_re - Started: sample 214, replica 6 2023-05-21 13:35:07 - INFO - sync_re - Finished: sample 214, replica 6 (duration: 44.85900000000038 s) 2023-05-21 13:35:07 - INFO - sync_re - Started: sample 214, replica 7 2023-05-21 13:35:51 - INFO - sync_re - Finished: sample 214, replica 7 (duration: 44.35999999999967 s) 2023-05-21 13:35:51 - INFO - sync_re - Started: sample 214, replica 8 | |
| ID: 60465 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
I can't run ATM stuff at the moment. | |
| ID: 60466 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Need some more tasks for the coming week. RTS=0 | |
| ID: 60468 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
Need some more tasks for the coming week. RTS=0 All I get now is QUICO and that dies. | |
| ID: 60469 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
These units still crash on restart, but it otherwise seems to run fine: | |
| ID: 60551 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
When will atm be unsuspended? | |
| ID: 60586 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
Good evening, only on one of my PCs with Windows 11, I7-13700KF and RTX 2080 Ti, none of the GPUGRID ATMbeta tasks (CUDA 1121) can be processed. By now more than a hundred have ended after a few tens of seconds. Other tasks (for example based on CUDA 1131) are also processed on this PC and without any problems. I have no idea what could be causing it so I do not know how to fix it. Thanks in advance to anyone who can help me solve the problem. I just had a theory that cmd could fail because both you and i had set default command processor to Windows terminal instead of Console Window Host. Unfortunately i can't test it because there are no more ATM tasks. | |
| ID: 60588 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
Didn't help. | |
| ID: 60589 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
Didn't help. It could be a hardware problem (processor, RAM, etc), not software. I have 2 computers crunching here. One is a Core 7 intel, with 32 Gigs RAM, and it completes both ACEMDs and ATMbetas successfully. https://www.gpugrid.net/results.php?hostid=608721 There other is an AMD Phenol II, with 16 Gigs RAM, and it completes ACEMDs successfully, while ATMbetas error out. (I can't put any more RAM on this MB.) https://www.gpugrid.net/results.php?hostid=607570 They both have the same OS. | |
| ID: 60590 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
In my case it crashes instantly on Wrapper: running C:/Windows/system32/cmd.exe (/c call run.bat) | |
| ID: 60591 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
These units still crash when shutdown and then restarted. The progress bar goes to 100% done after a few minutes, when you get to the subsequent units in the thread. Looks like nothing has been updated. | |
| ID: 60597 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
ATM Beta still crashes after 40 seconds on a RTX 4080. | |
| ID: 60598 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
after some time, today I resumed crunching ATM tasks. | |
| ID: 60599 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
the estimate time to completion is too long. so BOINC thinks they wont finish by their listed 5 day deadline. that's why. you can try editing the DCF in the client state file manually, or just wait for it to adjust itself. | |
| ID: 60600 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
the estimate time to completion is too long. so BOINC thinks they wont finish by their listed 5 day deadline. ... that's what I suspected first (I had that before on another machine), then I took a look at the times, and surprise: right now, a task has been running for 2:32 hrs, indicated completion time: 34:50 minutes(!). So the problem must be somewhere else :-( | |
| ID: 60601 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
the estimate time to completion is too long. so BOINC thinks they wont finish by their listed 5 day deadline. ... it has to do with the estimated completion time of the task it's trying to download + the tasks you have. not just the tasks you have. a brand new task might say it will take 90hrs to finish. you have 34hrs remaining on your work. so it thinks it would be 5.1 days before the new task would finish, so it decides to not download any. ____________ | |
| ID: 60602 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
... you have 34hrs remaining on your work. ... NOT 34hrs, but 34 minutes ! | |
| ID: 60603 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
... you have 34hrs remaining on your work. ... that's inconsequential, it was just an example. the point was that it depends mostly on the time estimate of the task to be downloaded. which could be in excess of 5 days already and you're in the same situation. several of mine show initial estimates like 200+ days. ____________ | |
| ID: 60604 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
right now, a task has been running for 2:32 hrs, indicated completion time: 34:50 minutes(!). When trying to download a second task, set the "Store at least X days of work" parameter at BOINC local preferences as tight in excess as possible to remaining calculated time for the task in progress. At your example: about 34 minutes remaining, try setting the "Store at least X days of work" parameter to 0.03 days (about 43 minutes). And parameter "Store up to an additional X days of work" set to 0.00  | |
| ID: 60605 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
@ ServicEnginIC, thanks for your hints. | |
| ID: 60606 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) | |
| ID: 60610 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) I have question regarding the minimum hardware requirements (i.e. Amount, speed, type of RAM, CPU speed and type, motherboard speed and requirements, etc.) for the computer to be able to complete successfully, these units for either windows and linux OS? One of my computers has been running these units successfully, the other has not. They both have the same OS, but have different hardware. I just want to know the limits. | |
| ID: 60611 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) I'm not sure to be the most adequate to answer this question but I might try my best. AFAIK it should run anywhere, maybe the issue is more driver related? We recently tested on 40 series GPUs locally and it run fine, since I saw some comments in the thread. | |
| ID: 60612 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
this kind of error | |
| ID: 60613 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) Both computers are running the same driver, and both computers have the same type of video card rtx 2080ti. Here is the portion from the log from the computer that has the errors: Running command git clone --filter=blob:none --quiet https://github.com/raimis/AToM-OpenMM.git /var/lib/boinc-client/slots/0/tmp/pip-req-build-9y8_6t1d Running command git rev-parse -q --verify 'sha^d7931b9a6217232d481731f7589d64b100a514ac' Running command git fetch -q https://github.com/raimis/AToM-OpenMM.git d7931b9a6217232d481731f7589d64b100a514ac Running command git checkout -q d7931b9a6217232d481731f7589d64b100a514ac error: subprocess-exited-with-error × python setup.py egg_info did not run successfully. │ exit code: -4 ╰─> [0 lines of output] [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. error: metadata-generation-failed × Encountered error while generating package metadata. ╰─> See above for output. note: This is an issue with the package mentioned above, not pip. hint: See above for details. 15:34:05 (42979): bin/bash exited; CPU time 3.604100 15:34:05 (42979): app exit status: 0x1 15:34:05 (42979): called boinc_finish(195) </stderr_txt> https://www.gpugrid.net/result.php?resultid=33535521 Would this be a software or hardware problem? | |
| ID: 60614 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) several long standing and well discussed issues are still unresolved with these tasks. in reducing priority: 1. task checkpointing still does not work properly. it may be writing to the checkpoint file, but it does not ever resume from the checkpoint. any pausing or suspending work units for any reason will cause it to error out when it attempts to resume. this is an issue for anyone who runs multiple projects (BOINC will occasionally pause in-progress units to crunch other projects) or needs to shutdown their computer for updates or whatever. 2. runtime progress reporting ONLY works for the first batch "0-5" labelled tasks. anything "1-5" though "4-5" do not work properly, they jump immediately to 100% and stay there until it is complete. this makes it hard to know how long they will run 3. estimated flops setting on these tasks is probably way too high leading to crazy high runtime estimates. this could likely cause indirect issues with the BOINC client either not fetching work properly or not managing other projects properly. 4. many batches are being sent out malformed occasionally. leading to errors. seems most are due to incorrect formatting or naming. stuff like this: "+ tar cjvf restart.tar.bz2 'r*/*.xml' tar: r*/*.xml: Cannot stat: No such file or directory" these are things I've seen constant complaints about every time these tasks come back. I would highly recommend that you guys attach a computer to the project like a normal user so that you can experience them first hand and properly troubleshoot them. ____________ | |
| ID: 60615 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
Yes, the constant WUs throwing errors! Luckily most at the beginning, but some run for quite some time before erroring out. More Errors than Valid is a huge waste of resources and time for everyone. | |
| ID: 60616 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
Sorry for missing out for a while. We were testing ATM in a setup not available for GPUGRID. But we're back to crunching :) ________ Could you please make these tasks be able to suspend? Monsoons in my part of the World and every time it rains there is a power outage. Even though in Preferences I have set it to keep WU in Memory while on batteries, every time the power goes WU ends up with an error. Now 100% of the WUs at my end in error are due to this reason. | |
| ID: 60617 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Yes, the constant WUs throwing errors! Luckily most at the beginning, but some run for quite some time before erroring out. More Errors than Valid is a huge waste of resources and time for everyone. mentioning the "waste of resources": "ValueError: Energy is NaN." has happened again quite a lot in the recent past. Mostly after between 1-1/2 and 2 hours runtime. Given that electricity cost has trippled here since last year, such waste has become quite expensive :-( | |
| ID: 60618 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
Another new batch...same old Errors. | |
| ID: 60619 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
Valid 17, error 26. I know it makes no difference; plenty of computers are standing by and it will get done. | |
| ID: 60620 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
AFAIK it should run anywhere, maybe the issue is more driver related? We recently tested on 40 series GPUs locally and it run fine, since I saw some comments in the thread. My driver for the RTX 4080 under Win11 is 536.23 All units error out after about 40 seconds. I do not see this on a 2070S nor on a 3070 Laptop. | |
| ID: 60621 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
AFAIK it should run anywhere, maybe the issue is more driver related? We recently tested on 40 series GPUs locally and it run fine, since I saw some comments in the thread. It would be helpful if you unhid your computers so we could examine the output files to get a clue on why the tasks are failing on your 40 series card, | |
| ID: 60622 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
It would be helpful if you unhid your computers so we could examine the output files to get a clue on why the tasks are failing on your 40 series card, Done. I just ran 2 fresh WUs that errored out as usual. Thank you very much. | |
| ID: 60623 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
Wasn't helpful. You don't have any result output at all. The tasks never even get to start the setup process. They just exit immediately. Quico needs to reexamine his statement that the 40 series cards are working OK on the ATMbeta tasks. [Edit] I would reset the project to start with in the hope that the task and app packages gets downloaded again. Maybe the necessary Python environment never got set up correctly initially. | |
| ID: 60624 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
Project reset and tried two new WU. Same result - error after a few seconds. | |
| ID: 60625 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Quico needs to reexamine his statement that the 40 series cards are working OK on the ATMbeta tasks. they do. look at the leaderboard. many 40-series hosts returning valid work from both linux and Windows. ____________ | |
| ID: 60626 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
OK, so 40 series works fine for both Windows and Linux. | |
| ID: 60627 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Does the 4080 run other projects gpu tasks without errors? | |
| ID: 60628 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Maybe a problem with BOINC itself. Might try a different BOINC version. | |
| ID: 60629 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
Does the 4080 run other projects gpu tasks without errors? Yes, it does without errors. PrimeGrid, SRBase, Einstein and WCG OPNG. BOINC was updated to 7.22.2 within this Beat phase - same result. | |
| ID: 60630 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Another new batch...same old Errors. forget Krembil - it's down most of the time. Too bad what happened to WCG :-( | |
| ID: 60632 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
|
It does not make any difference to Quico. The task will be completed on one or another computer and his science is done. It is our very expensive energy that is wasted but as Quico himself said, the science gets done who cares about wasted energy? | |
| ID: 60633 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
You also have the option to crunch something else if your time is wasted here. | |
| ID: 60634 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
You also have the option to crunch something else if your time is wasted here. I wish you would put a dirty sock where required. In Asia, the transmission of power is through overhead lines. They run red hot and expanded in our heat. Many people used to die due to electrocution. They switch off the grid. If the WU's cannot handle a suspension then there is no need for cati useless useless remarks. You also have the option of not running off with your writing skills. | |
| ID: 60636 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
If it hurts when you <do that> then the most obvious solution is to not <do that>. This applies to most things in life. | |
| ID: 60638 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
|
Ok, back from holidays. | |
| ID: 60651 | Rating: 0 | rate:
| |
|
Quico Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 28 Feb 23 Posts: 35 Credit: 0 RAC: 0 Level Scientific publications | |
It does not make any difference to Quico. The task will be completed on one or another computer and his science is done. It is our very expensive energy that is wasted but as Quico himself said, the science gets done who cares about wasted energy? I'm pretty sure I never said that about wasted energy. What I might have mentioned is that completed jobs come back to me and since I don't check what happens to every WU manually then these crashes might go under my radar. As Ian&Steve C. these app is in "beta"/not ideal conditions. Sadly I don't have the knowledge to fix it, otherwise I would. Errors on my end can be one I forget to upload some files (happened) or I sent jobs without equilibrated systems (also happened). By trial and error I ended up with a workflow that should avoid these issues 99% of the time. Any other kind of errors I can pass them to the devs but I can't promise much more apart from it. I'm here testing the science. | |
| ID: 60652 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
This might be more time consuming and I would not like to split them in even more chunks (might have a suspicion that this gives wonky results at some point) but if people see that they take too long time/space please let me know. I think that the most harmful risk is that excessively heavy tasks generate result files bigger than 512 MB in size. GPUGRID server can't handle them, and they won't upload... | |
| ID: 60653 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Absolutely, this is the biggest risk. Shame that you can't get Gianni or Toni to reconfigure the website html upload size limit to 1GB. | |
| ID: 60654 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
Can you at least fix the "daily quota" limit or whatever it is that prevents a machine from getting more WUs? 8/17/2023 10:25:12 AM | GPUGRID | This computer has finished a daily quota of 14 tasks After all, it is your WUs that are Erroring out by the hundreds and causing this "daily quota" to kick in. Seems this batch is even worse than before. | |
| ID: 60655 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The tasks I received this morning are running fine, and have reached 92%. Any problems will be the result of the combination of their tasks and your computer. The quota is there to protect their science from your computer. Trying to increase the quota without sorting out the cause of the underlying problem would be counter-productive. | |
| ID: 60656 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
It seems windows hosts in general seem to have a lot more problems than Linux hosts. | |
| ID: 60657 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
It seems windows hosts in general seem to have a lot more problems than Linux hosts. Depends what the error is. I looked at host 553738: Coprocessors [4] NVIDIA NVIDIA GeForce RTX 2080 Ti (11263MB) driver: 528.2 and tasks with openmm.OpenMMException: Illegal value for DeviceIndex: 1 BOINC has a well-known design flaw: it reports a number of identical GPUs, even if in reality they're different. And this project's apps are very picky about being told exactly what sort of GPU they've been told to run on. So, if Device_0 is a RTX 2080 Ti, and Device_1 isn't, you'll get an error like that. The machine has completed other tasks today, presumably on Device 0, although the project doesn't report that for a successful task. | |
| ID: 60658 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Just anecdotally, most issues reported seem to be coming from windows users with ATMbeta. | |
| ID: 60659 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
Most of the errors so far have occurred on the otherwise reliable Linux machine. | |
| ID: 60661 | Rating: 0 | rate:
| |
|
Freewill Send message Joined: 18 Mar 10 Posts: 13 Credit: 12,377,242,894 RAC: 92,818,842 Level Scientific publications | |
|
I have 11 valid and 3 error so far for this batch of tasks. I am getting the "raise ValueError('Energy is NaN." error. This is for Ubuntu 22.04 and single GPU or 2 identical GPU systems. What really hurts is the tasks are running a long time and then the error comes. | |
| ID: 60662 | Rating: 0 | rate:
| |
|
mmonnin Send message Joined: 2 Jul 16 Posts: 333 Credit: 4,973,676,065 RAC: 17,334,673 Level Scientific publications | |
|
I completed my first of these longer tasks in Win10. Sometimes this PC completes tasks failed by others and the opposite also happens. | |
| ID: 60663 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
This is a new one on me: task 33579127 | |
| ID: 60664 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
one strange thing I noticed when I re-started downloading and crunching tasks on 2 PCs yesterday evening: | |
| ID: 60665 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
BOINC thought it was a new host. | |
| ID: 60666 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
I think that the most harmful risk is that excessively heavy tasks generate result files bigger than 512 MB in size. I see that one of the issues that Quico seems to have addressed is just this one. At this two GTX1650 GPU host, I was processing these two tasks: syk_m39_m14_1-QUICO_ATM_Mck_Sage_2fs-1-5-RND8946_0, with this characteristics: syk_m31_m03_2-QUICO_ATM_Mck_GAFF2_2fs-1-5-RND5226_0, with this characteristics To test the sizes of the generated result files, I suspended network activity at BOINC Manager. And now there are two only result files per task, both being much lighter than previous batches. Excessively heavy result files problem solved, and by the way, less stress for server storage. | |
| ID: 60667 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Yes, I saw that and it looks like good news. But, I would say, unproven as yet. This new batch have varying run times, according to what gene or protein is being worked on - the first part of the name, anyway. | |
| ID: 60668 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
|
I am a bit curious what's going on with this 1660 super host. I occasionally check the error out units to make sure it's not just always failing on my hosts and I noticed more than once some host would finish it super fast. It happened to some of my own valid WUs too. While this sometimes happens, what I haven't seen until now is a host that either errors out, or finishes super fast: https://www.gpugrid.net/results.php?hostid=610334 | |
| ID: 60671 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
|
What's with the new error/issue... 8/22/2023 12:49:47 PM | GPUGRID | Output file syk_m12_m14_3-QUICO_ATM_Mck_Sage_v3-1-5-RND3920_0_0 for task syk_m12_m14_3-QUICO_ATM_Mck_Sage_v3-1-5-RND3920_0 absent Of course, may not ne new...I just saw it in my log after having a string of errors. | |
| ID: 60672 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
There appears to be a flaw or weakness in the application right at the end of the finishing up stage where the app needs to tar the output file. | |
| ID: 60673 | Rating: 0 | rate:
| |
|
Art_Brown Send message Joined: 3 Jun 09 Posts: 4 Credit: 1,074,953,114 RAC: 0 Level Scientific publications | |
|
ATMbeta tasks show 100% complete but do not finish, and Task Manager shows 'normal' working CPU loads (5 to 6% in my case) (12 core, 16 logical). I abort the runs and stop accepting new work for a week or so hoping the next batch finishes and uploads, but it might be an issue with my PC. | |
| ID: 60674 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Yes. That is - sadly - normal for the current tasks in this series. Ultra-long tasks were split into bite-sized chunks - you can tell which chunk you're running from the task name. They're split into 0-5 to 4-5 (towards the end of the task name: there's no 5-5). | |
| ID: 60675 | Rating: 0 | rate:
| |
|
Art_Brown Send message Joined: 3 Jun 09 Posts: 4 Credit: 1,074,953,114 RAC: 0 Level Scientific publications | |
|
Hi Richard and thanks for the info. | |
| ID: 60676 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
The ATMbeta tasks cannot be stopped during processing or they will error out. | |
| ID: 60677 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
|
I also pause computing during peak hours, both for cost and not to put more load onto the grid at the wrong time. I guess when to stop fetching work from gpugrid so that WU finishes before the peak hours begin. | |
| ID: 60683 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
If it hurts when you <do that> then the most obvious solution is to not <do that>. This applies to most things in life. The sad part is that you are extra smart. | |
| ID: 60684 | Rating: 0 | rate:
| |
|
KAMasud Send message Joined: 27 Jul 11 Posts: 137 Credit: 523,901,354 RAC: 0 Level Scientific publications | |
I also pause computing during peak hours, both for cost and not to put more load onto the grid at the wrong time. I guess when to stop fetching work from gpugrid so that WU finishes before the peak hours begin. You cannot predict but someone extra smart will come and post irrelevant BS. 28 WU each crunched eight hours then errored out. Multiply 28 by 8 then the power tariff. All wasted. | |
| ID: 60685 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
this morning, a ATM on a GTX980ti errored out after more than 10 hours :-((( | |
| ID: 60686 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
this morning, a ATM on a GTX980ti errored out after more than 10 hours :-((( Similar here after 11,363.13 seconds on a RTX 2070S for Unit 33589476. I understand that it can happen in a Beta project. However, I would expect that the developer irons out the most common errors such as 'Energy is NaN', progress indication jumping to 100%, wrong remaining runtime indication, RTX4xxx errors on Windows - to name a few. | |
| ID: 60687 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I also pause computing during peak hours, both for cost and not to put more load onto the grid at the wrong time. I guess when to stop fetching work from gpugrid so that WU finishes before the peak hours begin. I’m sure doing the same thing over and over and expecting a different result is the solution :) ____________ | |
| ID: 60688 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
I also pause computing during peak hours, both for cost and not to put more load onto the grid at the wrong time. I guess when to stop fetching work from gpugrid so that WU finishes before the peak hours begin. You mean like releasing batch after batch after batch of WUs with the same issues that people have been complaining about for how long now? :) | |
| ID: 60689 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
It’s beta. Accept it or move on. | |
| ID: 60690 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
It’s beta. Accept it or move on. the question though is how much longer it will be beta. Isn't the reason for beta that the developper of a tool is working on it in order to eliminate problems? Here, not much seems to have been done so far. Always the same errors and problems, none of them have been solved after so long time :-( | |
| ID: 60691 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
here the next one: | |
| ID: 60692 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
It’s beta. Accept it or move on. Could be forever . . . does not matter as the science still gets done. Either accept failures with a beta app or move on. | |
| ID: 60693 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Judging by the number of tasks which have passed through the system over the past week (and yet more have just been added), it would appear that the scientific part of the project is now operating in 'production' mode, rather than 'beta' mode. | |
| ID: 60694 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Judging by the number of tasks which have passed through the system over the past week (and yet more have just been added), it would appear that the scientific part of the project is now operating in 'production' mode, rather than 'beta' mode. + 1 | |
| ID: 60695 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
It’s beta. Accept it or move on. This excuse/reason has been used for too long now. It's getting old and I'm sick of people letting devs/admins of projects slide by with crap apps instead of fixing them like they know they should. | |
| ID: 60696 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
then don't support the project? and move on? | |
| ID: 60697 | Rating: 0 | rate:
| |
|
I totally agree. | |
| ID: 60698 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Quico has said multiple times that he doesn't know how to fix it (the runtime/% and checkpointing). complaining more wont get it fixed. at this point, it's your own choice to run this or not. if you don't like it, don't do it. Quico is a research scientist - and at least he communicates with us (thank you). I wouldn't expect him to be an expert in project administration. That's why my comment was explicitly directed at the (silent) administrators. | |
| ID: 60699 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
That's why my comment was explicitly directed at the (silent) administrators. yes, they are very silent; and obviously they don't care whether or not we volunteers are confronted with annoyingly faulty tasks :-( | |
| ID: 60700 | Rating: 0 | rate:
| |
|
bluestang Send message Joined: 13 Apr 15 Posts: 10 Credit: 2,542,462,606 RAC: 0 Level Scientific publications | |
Quico has said multiple times that he doesn't know how to fix it (the runtime/% and checkpointing). complaining more wont get it fixed. at this point, it's your own choice to run this or not. if you don't like it, don't do it. Yes exactly. My comments are about the Admins/Devs...not Quico. And as Richard has said, at least he communicates with us and does what he can. It's a shame the others can't, or won't. | |
| ID: 60701 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
As I understand it, GPUgrid is now just one of several projects under the computational science lab and the developers are mostly involved with Acellera | |
| ID: 60704 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
the next problem I have been faced with for several days: the download of a task takes forever. Speed is about 10 kB/ps :-( | |
| ID: 60705 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
the next problem I have been faced with for several days: the download of a task takes forever. Speed is about 10 kB/ps :-( right now, the download of a task has been taking 1:40 hrs so far and the progress is about 55 %. That's ridiculous :-( What's going on at GPUGRID? Are the servers breaking down? | |
| ID: 60706 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Lots of tasks going out to hosts and lots of results returning. | |
| ID: 60707 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Lots of tasks going out to hosts and lots of results returning. currently only 171 users are receiving and sending tasks with several hours between receiving and sending. So we are definitely not talking about outragiously high network traffic. Something seems to be wrong with their servers. | |
| ID: 60708 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
The download times you mentioned are very long and not at all what I am experiencing. | |
| ID: 60711 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
I had previously reported that ATMbeta fails after about 40 seconds on my RTX4080 under Windows 11, while I see other users getting valid results on different RTX40x0s. | |
| ID: 60712 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
The download times you mentioned are very long and not at all what I am experiencing. here, some downloads get done rather quickly, some others take forever and sometimes they error out after long time. STDERR then says the following: <message> WU download error: couldn't get input files: <file_xfer_error> <file_name>cmet_m16_m20_3-QUICO_ATM_Mck_GAFF2_v4-3-cmet_m16_m20_3-QUICO_ATM_Mck_GAFF2_v4-2-5-RND1222_1</file_name> <error_code>-119 (md5 checksum failed for file)</error_code> </file_xfer_error> </message> The download speed of my ISP is 300 Mbit/s which normally works well as long as the download server at the other end has no problems. | |
| ID: 60714 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
since yesterday, I face a new problem: | |
| ID: 60715 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
The download times you mentioned are very long and not at all what I am experiencing. here an example of the download problem which I keep facing: https://www.gpugrid.net/result.php?resultid=33613115 Erstellt 3 Sep 2023 | 11:20:22 UTC Gesendet 3 Sep 2023 | 12:29:54 UTC Empfangen 3 Sep 2023 | 12:43:06 UTC since the download still did not get finished after almost 70 minutes, it broke off :-( I think GPUGRID needs to work on their servers quickly. | |
| ID: 60716 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
What do you have for transfers in your cc_config.xml file? | |
| ID: 60717 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
What do you have for transfers in your cc_config.xml file? it's 8 connections per project and the downloads get even worse now. Several times now downloads have stopped after proceeding extremely slowly, with "download failed" in the BOINC manager :-( | |
| ID: 60719 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
the BOINC event log keeps saying: project servers may be temporarily down. | |
| ID: 60720 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Still believe the issue is local to you. In all the while you have reported issues with the downloads, I have not experienced any issues or backoffs. | |
| ID: 60721 | Rating: 0 | rate:
| |
|
Stoneageman Send message Joined: 25 May 09 Posts: 224 Credit: 34,057,224,498 RAC: 0 Level Scientific publications | |
|
I regularly get backoffs on transfers, so it's not just you. :top "C:\Program Files\BOINC\boinccmd" --host 127.0.0.1:31416 --passwd "yourpasswordhere" --network_available TIMEOUT /T 300 goto top Create a text file with this script. Edit to suit your install. Save as a batch file then double click to run it. | |
| ID: 60726 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i started processing ATM again on my known stable host (Linux Ubuntu LTS, EPYC + 4x A4000). | |
| ID: 60727 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
The uploads are definitely slow, upwards of 25 minutes for an 86 Meg files. I just notice it this weekend. Until last week, the uploads were taking less than a minute for this particular file. Though downloads still take less than a minute for me. | |
| ID: 60728 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Any idea why there is no longer any Stderr information on failed tasks? | |
| ID: 60734 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
likely something specific to that host, nothing to do with the project. none of my errors exhibit that. | |
| ID: 60735 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Also finally noticing the slow downloads/uploads for tasks for the project that many have been complaining about for a week. | |
| ID: 60736 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
Getting the "Energy is NaN" error doesn't necessarily mean that the unit is a bad one. It means that unit more sensitive to failure. | |
| ID: 60739 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
BTW: The uploads are running at normal speeds, when there is very little work. The project obviously needs more bandwidth. Download problems are still persisting, a recent example see here: https://www.gpugrid.net/result.php?resultid=33624287 | |
| ID: 60740 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Getting the "Energy is NaN" error doesn't necessarily mean that the unit is a bad one. It means that unit more sensitive to failure. this may be the case; but after such long time, the developper should have been able to iron out this unusual extremely high sensivity. 2 or 3 weeks ago I stopped crunching ATMs on one of my hosts, after about every other task had failed, for unknown reason (no overclocking, no other tasks from other projects running). Now I am experiencing the curious situation on the other two hosts, that since - as opposed to until short time ago - no tasks from other projects are running (because there are none available), the dropout rate of ATMs even increased. No idea how come. And if this happens after several hours (which it does), it is more than annoying. If the situation continues like this, I will stop crunching ATMs also on these other two hosts, coming back only once the developper has improved the performance of the ATMs. Too bad that GPUGRID has stopped all other sub-projects like Python or ACEMD (both 3 and 4). I have been with GPUGRID for almost 9 years, but during this period of time, the situation has never been as bad aa it has been in the recent past, strange server problems included :-( No idea what's going on there ??? | |
| ID: 60741 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
I added up the runtimes of tasks that failed with "energy is NAN" alone on September 11: | |
| ID: 60742 | Rating: 0 | rate:
| |
|
It may not be nice but it's part of beta testing | |
| ID: 60743 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
It may not be nice but it's part of beta testing well, as already discussed here earlier: ATM has run as beta for half a year now. So, at some point the ongoing problems could be solved, right? | |
| ID: 60744 | Rating: 0 | rate:
| |
It may not be nice but it's part of beta testing Yes you could be right in what you are saying. Nevertheless the application is still in "Beta" so errors are still likely to show up every now and then or lots. | |
| ID: 60745 | Rating: 0 | rate:
| |
|
A couple of my ATM tasks (my only GPUgrid tasks for a loooong time) failed with this error: openmm.OpenMMException: Unknown property 'version' in node 'IntegratorParameters' | |
| ID: 60746 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
A couple of my ATM tasks (my only GPUgrid tasks for a loooong time) failed with this error: openmm.OpenMMException: Unknown property 'version' in node 'IntegratorParameters' one thing you can be happy about: theses tasks seem to fail after a few minutes, and not after many hours as it often is the case with the "Engergy is NAN" error. So not much waste of resources. | |
| ID: 60747 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Two errors so far with today's new batch. Both of the form FileNotFoundError: [Errno 2] No such file or directory: 'MCL1_mXX_mXX_0.xml' | |
| ID: 60748 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Just a FYI here for an interesting observation of two tasks run on a host where the first task finished up and reported correctly. + echo 'Save output' + tar cjvf output.tar.bz2 run.log r0/MCL1_m27_m05.out r1/MCL1_m27_m05.out r10/MCL1_m27_m05.out r11/MCL1_m27_m05.out r12/MCL1_m27_m05.out r13/MCL1_m27_m05.out r14/MCL1_m27_m05.out r15/MCL1_m27_m05.out r16/MCL1_m27_m05.out r17/MCL1_m27_m05.out r18/MCL1_m27_m05.out r19/MCL1_m27_m05.out r2/MCL1_m27_m05.out r20/MCL1_m27_m05.out r21/MCL1_m27_m05.out r3/MCL1_m27_m05.out r4/MCL1_m27_m05.out r5/MCL1_m27_m05.out r6/MCL1_m27_m05.out r7/MCL1_m27_m05.out r8/MCL1_m27_m05.out r9/MCL1_m27_m05.out r0/MCL1_m27_m05.dcd r1/MCL1_m27_m05.dcd r10/MCL1_m27_m05.dcd r11/MCL1_m27_m05.dcd r12/MCL1_m27_m05.dcd r13/MCL1_m27_m05.dcd r14/MCL1_m27_m05.dcd r15/MCL1_m27_m05.dcd r16/MCL1_m27_m05.dcd r17/MCL1_m27_m05.dcd r18/MCL1_m27_m05.dcd r19/MCL1_m27_m05.dcd r2/MCL1_m27_m05.dcd r20/MCL1_m27_m05.dcd r21/MCL1_m27_m05.dcd r3/MCL1_m27_m05.dcd r4/MCL1_m27_m05.dcd r5/MCL1_m27_m05.dcd r6/MCL1_m27_m05.dcd r7/MCL1_m27_m05.dcd r8/MCL1_m27_m05.dcd r9/MCL1_m27_m05.dcd tar: run.log: file changed as we read it + true + echo 'Save restart' + tar cjvf restart.tar.bz2 r0/MCL1_m27_m05_ckpt.xml r1/MCL1_m27_m05_ckpt.xml r10/MCL1_m27_m05_ckpt.xml r11/MCL1_m27_m05_ckpt.xml r12/MCL1_m27_m05_ckpt.xml r13/MCL1_m27_m05_ckpt.xml r14/MCL1_m27_m05_ckpt.xml r15/MCL1_m27_m05_ckpt.xml r16/MCL1_m27_m05_ckpt.xml r17/MCL1_m27_m05_ckpt.xml r18/MCL1_m27_m05_ckpt.xml r19/MCL1_m27_m05_ckpt.xml r2/MCL1_m27_m05_ckpt.xml r20/MCL1_m27_m05_ckpt.xml r21/MCL1_m27_m05_ckpt.xml r3/MCL1_m27_m05_ckpt.xml r4/MCL1_m27_m05_ckpt.xml r5/MCL1_m27_m05_ckpt.xml r6/MCL1_m27_m05_ckpt.xml r7/MCL1_m27_m05_ckpt.xml r8/MCL1_m27_m05_ckpt.xml r9/MCL1_m27_m05_ckpt.xml 16:23:56 (1259959): bin/bash exited; CPU time 6653.704111 16:23:56 (1259959): called boinc_finish(0) And the task https://www.gpugrid.net/result.php?resultid=33626029 that failed later in the same slot. + echo 'Save output' + tar cjvf output.tar.bz2 run.log r0/MCL1_m09_m41.out r1/MCL1_m09_m41.out r10/MCL1_m09_m41.out r11/MCL1_m09_m41.out r12/MCL1_m09_m41.out r13/MCL1_m09_m41.out r14/MCL1_m09_m41.out r15/MCL1_m09_m41.out r16/MCL1_m09_m41.out r17/MCL1_m09_m41.out r18/MCL1_m09_m41.out r19/MCL1_m09_m41.out r2/MCL1_m09_m41.out r20/MCL1_m09_m41.out r21/MCL1_m09_m41.out r3/MCL1_m09_m41.out r4/MCL1_m09_m41.out r5/MCL1_m09_m41.out r6/MCL1_m09_m41.out r7/MCL1_m09_m41.out r8/MCL1_m09_m41.out r9/MCL1_m09_m41.out r0/MCL1_m09_m41.dcd r1/MCL1_m09_m41.dcd r10/MCL1_m09_m41.dcd r11/MCL1_m09_m41.dcd r12/MCL1_m09_m41.dcd r13/MCL1_m09_m41.dcd r14/MCL1_m09_m41.dcd r15/MCL1_m09_m41.dcd r16/MCL1_m09_m41.dcd r17/MCL1_m09_m41.dcd r18/MCL1_m09_m41.dcd r19/MCL1_m09_m41.dcd r2/MCL1_m09_m41.dcd r20/MCL1_m09_m41.dcd r21/MCL1_m09_m41.dcd r3/MCL1_m09_m41.dcd r4/MCL1_m09_m41.dcd r5/MCL1_m09_m41.dcd r6/MCL1_m09_m41.dcd r7/MCL1_m09_m41.dcd r8/MCL1_m09_m41.dcd r9/MCL1_m09_m41.dcd tar: run.log: file changed as we read it + true + echo 'Save restart' + tar cjvf restart.tar.bz2 'r*/*.xml' tar: r*/*.xml: Cannot stat: No such file or directory tar: Exiting with failure status due to previous errors 16:44:27 (15335): bin/bash exited; CPU time 58.042528 16:44:27 (15335): app exit status: 0x2 16:44:27 (15335): called boinc_finish(195) I want to bring attention to the part where it could not parse down the xml string correctly. + tar cjvf restart.tar.bz2 'r*/*.xml' tar: r*/*.xml: Cannot stat: No such file or directory | |
| ID: 60750 | Rating: 0 | rate:
| |
|
GoodOlClint Send message Joined: 28 Jul 22 Posts: 1 Credit: 213,150,800 RAC: 650,325 Level Scientific publications | |
|
Got the "Energy is NaN" error today. Interestingly the task jumped to 100% after just a few minutes, however it continued running for over two hours afterwards. When it completed it uploaded a 45 mb result file. | |
| ID: 60751 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Got the "Energy is NaN" error today. Here the same a few hours ago, after so many times before :-( It's really unbelievealbe that after this problem has happened on a regular basis for half a year now, the developper is still not willing/able to iron out this nasty error. | |
| ID: 60752 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
On September 5, Bedrich Hajek wrote: The uploads are definitely slow, upwards of 25 minutes for an 86 Meg files. I just notice it this weekend. Until last week, the uploads were taking less than a minute for this particular file. Though downloads still take less than a minute for me. Still nothing has changed. Despite of only very few new tasks available once in a while, downloads and uploads take forever (25-30 kb/s). So it's clear that traffic congestion is definitely not the reason. I am curious when the project management will finally move ahead and straighten out all the problems. Seemingly, it really needs a good kick in the ass to wake them up ... | |
| ID: 60753 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Complaining here is doing no good other than making the other forum participants tired of the constant diatribes. | |
| ID: 60754 | Rating: 0 | rate:
| |
|
[CSF] Aleksey Belkov Send message Joined: 26 Dec 13 Posts: 85 Credit: 1,229,981,270 RAC: 24,152 Level Scientific publications | |
Complaining here is doing no good other than making the other forum participants tired of the constant diatribes. Golden words However, it’s still no use, because as practice shows, no matter how you argue, such people will still pour out their dissatisfaction over and over again... | |
| ID: 60764 | Rating: 0 | rate:
| |
|
Nuadormrac Send message Joined: 21 Jul 12 Posts: 7 Credit: 399,771,758 RAC: 3,316 Level Scientific publications | |
|
Climate has routine trickle credits which come in, which is also verification that it's making it to the next checkpoint. Some climate models were weaks though, not hours... | |
| ID: 60767 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
It seems that today a new batch of ATMbeta tasks is on the field. | |
| ID: 60783 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
what I notice is: | |
| ID: 60784 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
We're still working on the first task in each sequence - 0-5, or now 0-10. This looks to be a big batch, so that may last some time. | |
| ID: 60785 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
what I notice is: Does that mean that ATM tasks are available now? I haven't received anything since.. May or June, if i remember correctly. Even now, i explicitly clicked the Update button - nothing. nVidia RTX3070 on Win 11, if that matters. | |
| ID: 60788 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
what I notice is: the tasks now are "ATMbeta". you need to go into your preferences and allow beta work. ____________ | |
| ID: 60789 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
That's been done long time ago. My current settings are: ACEMD 3: yes | |
| ID: 60790 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
That's strange. 'Server Status' page reports 1,296 unsent units, but my BOINC client doesn't receive any. This is what i have in the logs: 31/10/2023 11:11:12 PM | GPUGRID | Sending scheduler request: To fetch work. | |
| ID: 60791 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Got my first 1-10 task of this run - specifically, | |
| ID: 60792 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
Same here for JNK1_m06_m05_2-QUICO_ATM_Sch_AIMNet2_10-1-10-RND3720 - direct to 100%, whereas TYK2_m03_m15_1-QUICO_ATM_Sch_GAFF2_xTB_MM_False_v3-0-10-RND2341_3 progress worked just fine. | |
| ID: 60793 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
there's more to it. there are two options you need to select. make sure this one is checked: "Run test applications?" ____________ | |
| ID: 60794 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Same here for JNK1_m06_m05_2-QUICO_ATM_Sch_AIMNet2_10-1-10-RND3720 - direct to 100%, whereas TYK2_m03_m15_1-QUICO_ATM_Sch_GAFF2_xTB_MM_False_v3-0-10-RND2341_3 progress worked just fine. there's no need to reanalyze all this. it's been done ad nauseam many months ago and discussed over and over again. all of the behavior is known at this point. tasks in the "0" group will all process and count the progress naturally. tasks in "1+" groups will all jump to 100% after the extraction phase. but will complete successfully in the normal time if you leave it alone. the root cause very likely has to do with how they have decided to configure their asyncre.cntl file. using a relative value rather than absolute based on what group it's in. for all run types, the last line of this file is listed as just "MAX_SAMPLES = +70". it's very possible that the app is communicating to boinc the run percentage based on the ratio of current sample to max sample. so for all "0" runs, the current sample will be less than the max sample. 1 through 70. however, for all "1+" runs, the current sample will always be greater than max sample (71+). boinc can't report greater than 100% completion, so it jumps to 100% and stays there until the task is actually finished. ____________ | |
| ID: 60795 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Well that would match with what I'm seeing, if chunk 0 = 1-70 and chunck 1 = 71-140, then progress would run 0-1 in the first case, and 1-2 in the second (and probably 2-3 for chunck #2 and so on). If the app reports progress in that way, and they can just change it to subtract the chunck number, then that would bring all progress back to 0-1 range where it should be. Sounds like a reasonably easy fix - if there isn't more to it obviously, and if they have the time to do that... | |
| ID: 60796 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
Sure, i have it checked: Run test applications? I have both test and other applications, that's why i'm surprised to not have been receiving anything when WUs are available now.[/i] | |
| ID: 60799 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
what is your cache setting in BOINC? how much work are you asking for? I think with GPUGRID if you ask for "too much" you end up getting this response and getting nothing. if you're asking for something like 10 days of work, that might explain it. set your work cache to like 1 day or less. | |
| ID: 60800 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
I even removed the project from BOINC and re-added it, to no avail: 1/11/2023 9:46:37 AM | GPUGRID | New computer location: work | |
| ID: 60801 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
My settings are:
Are these settings too low? | |
| ID: 60802 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
those should be OK to get at least one task I think. as long as BOINC doesnt think they will take so long to miss the deadline. | |
| ID: 60803 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
My computing prefs: 1/11/2023 9:52:09 AM | | General prefs: using separate prefs for work | |
| ID: 60804 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
those should be OK to get at least one task I think. as long as BOINC doesnt think they will take so long to miss the deadline. My laptop used to crunch ATM tasks successfully in the past, before the summer break. Is there anything different now? I mean, system requirements - have they changed dramatically in terms of available memory and graphics cards? | |
| ID: 60805 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i see that the host is linking up to your "work" venue/location. verify that the settings for the work venue allow beta/test applications. | |
| ID: 60806 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
Your system seems not to be asking for ATMbeta tasks. | |
| ID: 60807 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
This 'work' profile is coming from WCG and doesn't have anything about beta-testing tasks. Besides, it didn't cause any issues in the past. Where else should i look? The logs show that it's GPUGrid that doesn't return me new tasks: 1/11/2023 12:02:55 PM | GPUGRID | No tasks are available for ATM: Free energy calculations of protein-ligand bindingThat is, to me it appears that my BOINC client sends requests to the server but receives nothing. I enabled debugging logs to BOINC, this is the output: 1/11/2023 12:05:39 PM | | [work_fetch] ------- start work fetch state -------Though i don't know what that means | |
| ID: 60808 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
Your system seems not to be asking for ATMbeta tasks.Thanks for the response. However, I checked earlier and confirmed that beta tasks were enabled: see my post Will appreciate any help in resolving this. | |
| ID: 60809 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
When properly configured, the message should say somethimg like this: 1/11/2023 12:02:55 PM | GPUGRID | No tasks are available for ATMbeta: Free energy calculations of protein-ligand binding Try following message #60725, and accessing to the specific links it contains to GPUGRID Project Preferences and GPUGRID Hosts Edit Preferences as stated for "Home" venue (for example), then change your host to "Home" location. This should work. | |
| ID: 60810 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
When properly configured, the message should say somethimg like this: this is exactly what I meant about checking the venue settings. many people do not know of the different venues or how they are set. the WCG supplied compute web preferences are not the same thing as the project-specific host venue preferences. you can make different selections for different venues to give folks the ability to have different computers crunch different things within the same project. if your 'home' or 'default' (blank) preferences are allowing ATMbeta, but the host is set to the work venue which does not allow ATMbeta, then you wont get them. you need to be mindful of what venue the host is set to, and what the specific settings for that venue are. goldfinch, go here: https://gpugrid.net/prefs.php?subset=project and you will see that there are 4 different venues to choose from (default/home/school/work). make sure you are settings the preferences to allow ATMbeta and test apps for the correct venue corresponding to your actual selected venue. you can see what venue it's set to here: https://gpugrid.net/hosts_user.php under the location column. (blank = default) ____________ | |
| ID: 60811 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
Thank you @Ian&Steve C. and @ServicEnginIC, i didn't realise that i was checking *default* profile, while my *venue* profile was *work*, and the latter didn't have Test tasks checkbox ticked. Tons of appreciation for your patience! Thank you very much! | |
| ID: 60812 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
there's no need to reanalyze all this. it's been done ad nauseam many months ago and discussed over and over again. all of the behavior is known at this point. Well, I did reanalyze it. Because I'm stubborn like that. But mainly because I failed to notice the 400+ posts hidden by default in this thread. :-D The good news: I came to the same conclusion as Richard Haselgrove's post: progress = float(isample - last_sample)/float(num_samples - last_sample) should fix it, but even better would be: progress = float(isample - last_sample + 1)/float(num_samples - last_sample + 1) Since that would make the denominator = number of samples in the batch (fractions of 1/70 instead of now 1/69) and would let the count go from 1->70 instead of 0->69. The bad news: None of the github repo's containing the above code, and being retrieved on WU start, contain any branch or issue aiming to fix the progress issue. So I'll test my code fix locally once more. First test seemed to work fine, but WU terminated on the NaN issue quickly. Then I'll raise an issue or a pull request on the appropriate Github repo to try and get it fixed there. Fingers crossed... | |
| ID: 60813 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
refresh my memory; | |
| ID: 60814 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
I think it's this section that has some problem, but I haven't fully digested exactly what it's doing yet. last_sample = self.replicas[0].get_cycle() ____________ | |
| ID: 60815 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
I think it's this section that has some problem, but I haven't fully digested exactly what it's doing yet. For normal units (0-whatever), MAX_SAMPLES will be "70" and last_sample = 1. In that case num_samples will be 70. isample iterating from 1->70 (inclusive). So my formula's denominator will be num_samples-last_sample + 1 or 70-1+1=70. The numerator (isample - last_sample + 1) goes from 1-1+1=1 until 70-1+1=70. So works for regular units. For additional units (>0-whatever), MAX_SAMPLES will be "+70" and last_sample will be 71 or 141 or... In that case the 'if num_samples.startswith("+")' clause will be triggered. num_extra_samples will be 70 and num_samples = num_extra_samples + last_sample - 1, giving 70 + 71 - 1 = 140 (or 210, or...) isample will iterate from 71->140 or 141->210 or... Denominator will be 140 - 71 + 1 = 70 or 210 - 141 + 1 = 70 or... Numerator will be 71-71+1=1 until 140-71+1=70, or 141-141+1=1 until 210-141+1=70, or... so in both cases, whatever the NUM_SAMPLES may be and whatever the first sample number may be, the progress will go from 1/NUM_SAMPLES to NUM_SAMPLES/NUM_SAMPLES and you will get a nice representative percentage. Except of course for the 0.199% added in the beginning for the unpack tasks... | |
| ID: 60818 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
did you follow the exact logic of the code all thr way through? or are you making some assumptions about how you think it works? | |
| ID: 60819 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
did you follow the exact logic of the code all thr way through? or are you making some assumptions about how you think it works? some comments added to follow along: num_samples = self.config['MAX_SAMPLES'] //HERE, num_samples is a string type! if num_samples.startswith("+"): num_extra_samples = int(num_samples[1:]) //[1:] will skip the first character of the string, so "+70" becomes "70". Then cast it into an integer type num_samples = num_extra_samples + last_sample - 1 // HERE, num_samples becomes an integer type. self.logger.info(f"Additional number of samples: {num_extra_samples}") else: num_samples = int(num_samples) //HERE, num_samples becomes integer self.logger.info(f"Target number of samples: {num_samples}") Doesn't matter if it's always "+70" for "0" tasks, last_sample will be 1, so num_samples = num_extra_samples + last_sample - 1 = 70 + 1 - 1 = 70. second, where do you get that last_sample=1? the code says last_sample = self.replicas[0].get_cycle(), but havent worked through the code yet to see what that actually evaluates to. can you elaborate with specific code paths to where "self.replicas[0].get_cycle()" = 1? The get_cycle() calculation is buried deep somewhere in the openMM libraries, so that I haven't managed to find exactly so I can prove it to you, however empirically (run.log) the "0" units start from cycle 1, the "1" units start from cycle 71. Also it doesn't really matter what the last_sample is. Let's say it's X. Then: num_samples = num_extra_samples + last_sample - 1 = 70 + X - 1 for isample in range(last_sample, num_samples + 1): => isample going from X until X + 70 - 1 (last integer of 'range' = excluded!) numerator = isample - last_sample + 1 => numerator going from X - X + 1 = 1 until X + 70 - 1 - X + 1 = 70 denominator = num_samples - last_sample + 1 = 70 + X - 1 - X + 1 = 70 so again progress will go from 1/70 to 70/70 replace 70 everywhere by an arbitrary value of 'MAX_VALUES' and again see that it doesn't matter whatever value is in there, it will work as expected. similarly with num_extra_samples, how does this equal to 70? it needs to be expanded from num_extra_samples = int(num_samples[1:]). not sure how the unbounded num_samples[1:] ends up being 70 in this case. Simple python string operation. Python is very clever and flexible with types. See my added comments in the first code snippet. num_samples = self.config['MAX_SAMPLES'] //HERE, num_samples is a string type! so it's a string here, but it's also an array of characters, where num_samples[0] will be a '+' in most cases. If it is a plus, then the IF-clause will trigger. num_extra_samples = int(num_samples[1:]) //[1:] will skip the first character of the string, so "+70" becomes "70". Then cast it into an integer type since the [0] is a '+', the [1:] will be "70", because if the end of the range is left empty, python 'knows' how long the string is and return until the end of the string but not beyond. So not 'unbounded', but 'implicitly bounded'. the int() part around it will re-type the "70" string into an integer 70. Assigning it to num_extra_samples will redefine that variable to 'int' (python magic again. And if it wasn't a '+' because MAX_VALUES was "70", then the 'else' clause will trigger: num_samples = int(num_samples) This will simply redefine the 'string' num_samples = "70" to an 'int' num_samples = 70 plug that into the example above and see that once again, the progess counter works as it should. | |
| ID: 60820 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
OK I'm following better (forgot that [1:] was omitting the first character and was thinking it was starting from one with the 0/1 mixup in what is "first"). I also couldn't find the get_cycle() routine. the way these tasks (scripts) are setup is very convoluted with how all the pieces of code get pulled in. importing bits of code from all over the place while the actual execution script is only a few lines long lol. really have to go down a rabbit hole to see what's happening. progress = float(isample)/float(num_samples - last_sample) ends up evaluating to a negative number since the num_samples will be 70 and the last sample will be >70. BOINC must be freaking out not knowing what to do with a negative number and calling it 100%. ____________ | |
| ID: 60821 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
OK I'm following better (forgot that [1:] was omitting the first character and was thinking it was starting from one with the 0/1 mixup in what is "first"). I also couldn't find the get_cycle() routine. the way these tasks (scripts) are setup is very convoluted with how all the pieces of code get pulled in. importing bits of code from all over the place while the actual execution script is only a few lines long lol. really have to go down a rabbit hole to see what's happening. Not negative no, but for "1+" units it will go beyond 1, and also (minor issue) increment in fractions of 1/69 instead of 1/70. Remember that num_samples = the max_samples parameter PLUS the last_sample! isample will go from 71-140 (or 141-210 etc) num_samples will be 140 or 210 or... last_sample will be 71 or 141 or... (but remember it doesn't really matter) so numerator 71=>140, denominator = 140 - 71 = 69 (or 210 - 141 = 69 or...) progress going from 71/69 until 140/69. Both > 1 so progress immediately jumps to 100%. | |
| ID: 60822 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
you're right I missed that bit. thanks. | |
| ID: 60823 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
you're right I missed that bit. thanks. That's basically how I'm testing it on my machine, but that would also imply somebody does that on the server side - adding the new atm.py and run.sh to the 'program package'. If you do it local, you also need to edit the boinc_state.xml in a boinc stopped state to bypass the code sign mechanism by inserting the correct md5sum and bytesize. FYI - run.sh is part of the server-generated input files for each WU. I'm not a programmer (or not anymore) so no real git skills, I did post an issue on the relevant github. If that's not picked up I'll try the pull request. | |
| ID: 60824 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
you can set <dont_check_file_sizes> in cc_config.xml and change anything you want in BOINC :) the only "BOINC" files you need to modify are the job.xml and you set it up to copy in the new run.sh after it extracts the input files (overwriting the original). only their tar file is checked, not the extracted contents. | |
| ID: 60825 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
you can set <dont_check_file_sizes> in cc_config.xml and change anything you want in BOINC :) the only "BOINC" files you need to modify are the job.xml and you set it up to copy in the new run.sh after it extracts the input files (overwriting the original). only their tar file is checked, not the extracted contents. Could be, although I'm reading this entry as "BOINC will check the integrity of this file (job.xml) to avoid tampering" <file> <name>job.xml.789bd8d206da56434f30083d18653299</name> <nbytes>828.000000</nbytes> <max_nbytes>0.000000</max_nbytes> <status>1</status> <signature_required/> <file_signature> 4b7b99c3260c591fe387d31d63158d0061c1b2fb5ef74395eada7cbb13c67b80 ...etcetera... 0e12d16e50df943339987857aa157b863ad1dcbb8712cd0e21c1968fc7ca561a . </file_signature> But it's a moot point, isn't it? It would potentially fix the issue for me or for anyone willing to put in the tweaking effort but not for the general user. I'll give it a try though. ;-) | |
| ID: 60826 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
i did the same thing on PythonGPU earlier this year. worked fine. | |
| ID: 60827 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
I had this task running for 3+ hours, and the laptop hang. I switched it off, back on, restarted BOINC - the task failed. I saw a post about tasks failing on restarts, but that task's output is different from mine. I have a few questions:
- if not, what's the purpose of the checkpoints? - what was wrong with my task after restart, and where/how can i get more detailed info, if needed? BOINC log doesn't show previous session's log, only the current where the task failed, but i need the logs that were at the time of hanging... As for the BOINC logs, here they are: 2/11/2023 7:22:35 PM | GPUGRID | [task_debug] task is running in processor group 0Should i activate other debug logs for such cases? Which, if yes? Thanks for your help. | |
| ID: 60828 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
At this time. Tasks cannot be restarted at all. This is because checkpointing is broken in some way that the devs haven’t figured out. Checkpointing is there because it’s *supposed* to work. It just doesn’t right now. Restarting for any reason will cause it to fail. | |
| ID: 60829 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
i did the same thing on PythonGPU earlier this year. worked fine. Well I tried, didn't work until I killed BOINC and edited the (new) filesize into client_state.xml. Even though the logfile clearly showed 'don't check filesizes' enabled, it failed due to job.xml size mismatch. Either a bug in the latest version, or some setting overriding it, like this one? <signature_required/> anyway, with the client_state size edit it does work. made these changes: <task> <application>C:/Windows/system32/cmd.exe</application> <command_line>/c copy ..\..\newrun.bat run.bat</command_line> <weight>1</weight> </task> <task> <application>C:/Windows/system32/cmd.exe</application> <command_line>/c call run.bat *.cntl</command_line> <setenv>CUDA_DEVICE=$GPU_DEVICE_NUM</setenv> <stdout_filename>run.log</stdout_filename> <weight>1000</weight> <fraction_done_filename>progress</fraction_done_filename> </task> the '*.cntl' command line added to run.bat is needed because the input config file xxxxx.cntl is actually hardcoded into run.bat for each WU - as run.bat is part of the WU file. So changes done to run.bat: at the beginning: set PARM1=%1 echo %PARM1% for %%A in (%PARM1%) do (set "CONFIG_FILE=%%A") echo %CONFIG_FILE% ...and deleted the original line setting the CONFIG_FILE variable This will load the (alphabetically last) config file - hoping they never include more than one... ;-) replace atm.py: @echo Replace atm.py copy ..\..\projects\www.gpugrid.net\atm_correct_progress.py Lib\site-packages\sync rename Lib\site-packages\sync\atm.py atm.py.orig rename Lib\site-packages\sync\atm_correct_progress.py atm.py @echo Run AToM python.exe Scripts\rbfe_explicit_sync.py %CONFIG_FILE% || goto EX22 and some exit handling to preserve relevant output files set LEVEL=%ERRORLEVEL% :EXIT copy run.log ..\..\projects\www.gpugrid.net\ copy stderr.txt ..\..\projects\www.gpugrid.net\ copy progress ..\..\projects\www.gpugrid.net\ exit %LEVEL% :EX14 set LEVEL=14 goto EXIT :EX22 set LEVEL=22 goto EXIT And now it's working fine with a 3-10 job (samples 211-280) and correct progress - no manual intervention. Thanks for the tip! | |
| ID: 60830 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Glad to see it’s working. A good amount of work for just a quality of life change though. And the changes for windows seem a bit more involved than they otherwise would be on Linux. Maybe the windows vs Linux client is why you couldn’t get it working initially? I assume you stopped and restarted BOINC after the change to cc_config, and not just a re-read config file. BOINC has to be restarted. | |
| ID: 60831 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Glad to see it’s working. A good amount of work for just a quality of life change though. Yeah, and it didn't even really bother me in the first place. :-D I just like a good puzzle. No response on the GIT issue yet, though.... | |
| ID: 60832 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
Dear [BAT] Svennemans, can you please consolidate your fix in 1 post? I got what you did with the config files, but i couldn't follow what you changed in Python files and where you put your new run.bat because i'm not familiar with the projects structure in BOINC and, particularly, with ATM projects. I also couldn't find the name and location of the modified config file. I think not only i but others, too, will appreciate the guide in the form of steps, especially considering that your system is Windows like mine... E.g.,
| |
| ID: 60838 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
Sure I can, goldfinch. A good amount of work for just a quality of life change Here goes: Procedure for Windows!
| |
| ID: 60839 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
Well... breath-taking! Thanks you so much! It works! I checked both run.bat and atm.py after BOINC restart - they were updated versions. However, this victory came with tears... While I was editing new version of run.bat, my laptop hang, with an ATM task being almost 100% complete... Maybe, overheating - it's a laptop, after all. I wish checkpoints could be fixed as easily as progress indicator!
| |
| ID: 60842 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Well... breath-taking! Thanks you so much! It works! I checked both run.bat and atm.py after BOINC restart - they were updated versions. However, this victory came with tears... While I was editing new version of run.bat, my laptop hang, with an ATM task being almost 100% complete... Maybe, overheating - it's a laptop, after all. I wish checkpoints could be fixed as easily as progress indicator! Yeah, those checkpoints would indeed be great. I did see on the dev's Github page an issue for preemption and checkpointing and a comment they're trying to fix it, so fingers crossed...
See Note 2 in section 6.3. :-D Long explanation: I had a couple of faults while debugging my procedure. BOINC then cleans out the slot directory faster than I could edit/validate the content of any files so I did it this way. I could quickly navigate into the Lib\site-packages\sync directory as the code was being unpacked and see if atm.py.orig popped up - or not. That was before I thought to include some errorhandling in run.bat. As for the ways how to determine a correct slot, here are my 2 cents (works with BOINC Manager; i don't know much about headless BOINC): That's very true and didn't even think about that. I just quickly browsed through the few slots directories I had on my system to find the correct one. But your explanation is useful for anyone not knowing how to recognize the correct slot content on sight. I'll edit my post to include it. <EDIT>: seems I can no longer edit my previous post. Oh well, they'll figure that one out I'm sure. ;-) For headless BOINC, you'd need to look into client_state.xml for an <active_task> section of gpugrid: <active_task> <project_master_url>https://www.gpugrid.net/</project_master_url> <result_name>Tyk2_jmc_28_jmc_27_1_RE-QUICO_ATM_Sch_GAFF2-3-10-RND3439_0</result_name> <active_task_state>1</active_task_state> <app_version_num>109</app_version_num> <slot>1</slot> ...
You're welcome, I'm happy it's useful to you - and maybe others. | |
| ID: 60843 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
I enabled checkpoints logging and discovered that checkpointing occurred right before uploading the results. That is, during computation checkpointing doesn't seem to occur (at least, according to debug logs).
That's not what i meant. My question was about why use this: @echo Replace atm.py instead of this: @echo Replace atm.py especially, seeing a similar approach in the config file modification: <command_line>/c copy ..\..\projects\www.gpugrid.net\newrun.bat run.bat</command_line>. In the second approach there are only 2 commands instead of 3, and result will be the same. If BOINC clears the slot directory, i don't see how using copy and subsequent rename can help, or how it will be affected differently compared to renaming the original and copying a corrected Python file with the correct name. Maybe, i'm missing something - after all, you debugged it, not i (: Thanks again. Next thing to solve is cooling the laptop. Any useful scripts for that? (joking:) | |
| ID: 60846 | Rating: 0 | rate:
| |
|
goldfinch Send message Joined: 5 May 19 Posts: 31 Credit: 506,869,685 RAC: 183,458 Level Scientific publications | |
|
Actually, your fix is more than simply improving quality of life. Because the progress is correctly displayed now, BOINC doesn't download next task immediately, but waits for some time. In my case, it downloaded the next task at ~95% of the current task, which is better because the task doesn't spend too much time in the queue. So, the fix also implicitly improves task management. | |
| ID: 60847 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
I enabled checkpoints logging and discovered that checkpointing occurred right before uploading the results. That is, during computation checkpointing doesn't seem to occur (at least, according to debug logs). Interesting. I do see that the Python code creates a simulation state checkpoint after every of the 70 samples. 2023-11-05 06:37:16 - INFO - sync_re - Finished: sample 288, replica 21 (duration: 13.26600000000326 s) 2023-11-05 06:37:16 - INFO - sync_re - Started: exchange replicas 2023-11-05 06:37:16 - INFO - sync_re - Replica 15: 18 --> 17 2023-11-05 06:37:16 - INFO - sync_re - Replica 21: 17 --> 18 2023-11-05 06:37:16 - INFO - sync_re - Finished: exchange replicas (duration: 0.031000000017229468 s) 2023-11-05 06:37:16 - INFO - sync_re - Started: update replicas 2023-11-05 06:37:30 - INFO - sync_re - Finished: update replicas (duration: 14.046999999962281 s) 2023-11-05 06:37:30 - INFO - sync_re - Started: write replicas samples and trajectories 2023-11-05 06:37:30 - INFO - sync_re - Finished: write replicas samples and trajectories (duration: 0.0 s) 2023-11-05 06:37:30 - INFO - sync_re - Started: checkpointing 2023-11-05 06:38:45 - INFO - sync_re - Finished: checkpointing (duration: 74.75 s) 2023-11-05 06:38:45 - INFO - sync_re - Finished: sample 288 (duration: 372.85899999999674 s) 2023-11-05 06:38:45 - INFO - sync_re - Started: sample 289 So the potential should be there to have more granular checkpoints. In the second approach there are only 2 commands instead of 3, and result will be the same. If BOINC clears the slot directory, i don't see how using copy and subsequent rename can help, or how it will be affected differently compared to renaming the original and copying a corrected Python file with the correct name. Maybe, i'm missing something - after all, you debugged it, not i (: The objective was not to prevent cleaning the slot directory, but to hopefully be able to see the atm.py.orig file pop in existance in the second before boinc cleans the slot. Granted I could have done that with one less command. I stand duly chastised for my reckless waste of processing cycles. ;-) Thanks again. Next thing to solve is cooling the laptop. Any useful scripts for that? (joking:) Yup: Try this - worked for me. :-) | |
| ID: 60850 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Another idiosyncrasy that has been less often discussed, and I knew in the back of my mind that this was the case, but since these tasks download some packages at runtime, this requires that you maintain internet connectivity for the tasks to run. I had a small issue with one host where it couldnt access the internet due to a network adapter issue, and tasks started to fail one by one (only in the setup phase I think, tasks that already downloaded what they need will run fine). | |
| ID: 60854 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
Yeah, I follow your logic. I can only assume they have a good reason for it. | |
| ID: 60857 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
nice, a PR should at least get someone's attention lol | |
| ID: 60858 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
nice, a PR should at least get someone's attention lol And so it finally did. :-) Pull request was accepted and merged into the original AToM-OpenMM/Master repo. All that's left now is for it to be merged into the proper repo that is retrieved at the execution of any WU, and progress % will be fixed. Which will obviously only be useful if ATMbeta task generation starts up again... Regarding one of your earlier questions: second, where do you get that last_sample=1? the code says last_sample = self.replicas[0].get_cycle(), but havent worked through the code yet to see what that actually evaluates to. can you elaborate with specific code paths to where "self.replicas[0].get_cycle()" = 1? I still haven't found the actual code position where it happens, but you can check that the starting cycle # is actually just read from the worker replica input file <taskname>.xml <Parameters ATMAcore=".0625" ATMAlpha="0" ATMDirection="1" ATMLambda1=".5" ATMLambda2=".5" ATMU0="0" ATMUbcore="2092" ATMUmax="4184" ATMW0="0" BiasEnergy="0" MonteCarloPressure="1" MonteCarloTemperature="300" REAlchemicalIntermediate="0" RECycle="0" REMDSteps="0" REPertEnergy="0" REPotEnergy="0" REStateId="0" RETemperature="0"/> This is copied into the r0-rxx replica dirs as checkpoint/restart files. The RECycle parameter will be 0, or 70 or whatever at the start and then increased at any new cycle/checkpoint. The reason checkpointing/restarting doesn't work is because between the BOINC wrapper and the actual working (Python) program, there is that run.bat/run.sh command shell process acting as a sort of in-between wrapper that doesn't properly forward communication between the BOINC client/wrapper and the actual python program leading to all sorts of mayhem that prevents the python program to gracefully exit and/or restart using its built-in checkpoint/restart functionality. That's because a restart will re-run the run.bat/run.sh in its entirety, overwriting part but not all of the existing working files, leaving the python program with inconsistent input data at restart leading to a crash. I'm taking a quick look to see if I can figure out some workaround, but the true fix would be running the python from the actual BOINC wrapper instead of using that .bat/.sh file in between. That would also imply, as you said before, having the AToM-OpenMM code downloaded as part of the project files instead of retrieved for any new WU. | |
| ID: 60880 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
that's great that someone finally noticed the PR and acted on it. maybe you need to drop a comment or something about merging it into the GPUGRID repo? ATM task generation IS ongoing right now. there appears to be a single small batch (~250 tasks) running right now. new tasks are generated when the previous segment is recieved. so the tasks in progress stays around 250, but the RTS shows 0 most of the time since so many hosts are asking for work. | |
| ID: 60881 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
A new batch was launched this afternoon (27 November 2023). File "/hdd/boinc-client/slots/1/bin/rbfe_explicit_sync.py", line 2, in <module> syk_m22_m32_3-QUICO_ATM_Sch_ANI-0-10-RND4131 syk_m07_m35_5-QUICO_ATM_Sch_ANI-0-10-RND4539 syk_m17_m25_4-QUICO_ATM_Sch_ANI-0-10-RND6268 syk_m43_m15_2-QUICO_ATM_Sch_ANI-0-10-RND5566 | |
| ID: 60882 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
can confirm. I have like 80+ errors from these. | |
| ID: 60883 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
A new batch was launched this afternoon (27 November 2023). Here, too, all tasks with name "syk..." are failing after about 1 minute :-( | |
| ID: 60884 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
nice, a PR should at least get someone's attention lol Please provide the direct link to the PR and the repo for the devs to incorporate your fix. | |
| ID: 60894 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
nice, a PR should at least get someone's attention lol i don't know why the devs need the users to spoon feed them their own code and repos. they accepted the PR and merged it already. it almost seems like theres little to no inter-team communication about what is going on. it's all here: https://github.com/Gallicchio-Lab/AToM-OpenMM/pull/56/ the PR was merged into this master on November 16th. but the tasks being distributed to users must be pulling from some other repo tag as the changes have not yet been reflected on subsequent tasks that we have received since then i don't have any tasks for ATM so i don't remember off hand what tag it was pulling. probably not master or the latest v8.1.0 since those have the fix. probably pulling the v8.1.0beta tag from October. ____________ | |
| ID: 60895 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
... the PR was merged into this master on November 16th. but the tasks being distributed to users must be pulling from some other repo tag as the changes have not yet been reflected on subsequent tasks that we have received since then Like all BOINC projects, GPUGrid has an applications page - it's part of the standard BOINC toolkit. That shows that the active ATM Beta code was installed for distribution on 27 Mar 2023 for Linux, and the following day for Windows. Now that the source code has been updated, it will need to be re-compiled into binary form and re-deployed. That's the current stumbling block. | |
| ID: 60896 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
... the PR was merged into this master on November 16th. but the tasks being distributed to users must be pulling from some other repo tag as the changes have not yet been reflected on subsequent tasks that we have received since then no that's not correct. you're not understanding how this application works. it's not the normal setup most boinc projects use. this "app" is NOT a compiled binary! it's just a bunch of python scripts. just watch how these tasks run and you will see. start from the wrapper and look what's actually happening. what gets distributed to users as the "app" is a baseline zip archive package that contains the conda python environment and some prepackaged libraries, etc. when BOINC runs, it's using the wrapper and associated job.xml file to start execution of the scripts. somewhere along the way in the long chain of script execution, it reaches out to github to download the necessary files and the one in question. wrapper -> unzip archive -> run script -> download stuff from github -> run more scripts that's why these tasks fail if you try to run them offline or without an internet connection. ____________ | |
| ID: 60897 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
... the PR was merged into this master on November 16th. but the tasks being distributed to users must be pulling from some other repo tag as the changes have not yet been reflected on subsequent tasks that we have received since then Correct, each WU downloads the ATM code on the fly. And the repo it is being pulled from is the "HEAD" of this repo: https://github.com/raimis/AToM-OpenMM. However, my pull request has been merged into https://github.com/Gallicchio-Lab/AToM-OpenMM (which is the ATM master repo), but NOT into the raimis one. The raimis one is still '17 commits behind' Gallicchio-Lab, and my fix is one of those 'todo' commits - check here: https://github.com/raimis/AToM-OpenMM/compare/master...Gallicchio-Lab%3AAToM-OpenMM%3Amaster So no compile needed. 2 things would potentially work: 1) Raimis merges the '17 commits' into his repo. That would then probably become the new 'HEAD' and WU's would automatically pull this (I hope) or the devs would potentially need to change the SHA code in run.bat/run.sh 2) The devs adapt the run.bat/run.sh to pull not from raimis 'HEAD', but from Gallicchio-Lab - but that might obviously have other side effects, i have no idea if they use raimis for a reason... Relevant code in run.bat/sh: @echo Install AToM set REPO_URL=git+https://github.com/raimis/AToM-OpenMM.git@d7931b9a6217232d481731f7589d64b100a514ac And for readers wondering where the hell that run.bat/sh comes from: it's part of each WU's "xxxxxx-input" file - which is just a bzipped tar file. | |
| ID: 60899 | Rating: 0 | rate:
| |
|
Bill F Send message Joined: 21 Nov 16 Posts: 32 Credit: 106,423,150 RAC: 20,848 Level Scientific publications | |
... the PR was merged into this master on November 16th. but the tasks being distributed to users must be pulling from some other repo tag as the changes have not yet been reflected on subsequent tasks that we have received since then So we all "Hope" that either option #1 or #2 happens.... Thank you for your efforts. Bill F | |
| ID: 60900 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
UPDATE: Seems that Raimis is reading the forum, or a little bird told him, because he has merged all commits. That's the good news. Now some dev still needs to update the commit SHA code in run.bat/run.sh to the new HEAD version 1aa4eb9c39de5e269da430949da2ef377b3d9ca2 New code needed in run.bat/sh: @echo Install AToM set REPO_URL=git+https://github.com/raimis/AToM-OpenMM.git@1aa4eb9c39de5e269da430949da2ef377b3d9ca2 Once that is fixed, the progress issue should be over and done with! | |
| ID: 60901 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Good news indeed. | |
| ID: 60902 | Rating: 0 | rate:
| |
|
Bill F Send message Joined: 21 Nov 16 Posts: 32 Credit: 106,423,150 RAC: 20,848 Level Scientific publications | |
Are there multiple who do Dev work for the project and is there away to get a "little bird" to talk to them ? Bill F | |
| ID: 60903 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
this morning, 2 of my Windows10 machines received ATMbeta tasks, and all of them failed after around 51 seconds (RTX3070) and around 81 seconds ((Quadro P5000). | |
| ID: 60913 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
this morning, 2 of my Windows10 machines received ATMbeta tasks, and all of them failed after around 51 seconds (RTX3070) and around 81 seconds ((Quadro P5000). still these faulty ATMs are being sent out, failing after short time. I now delisted them from my download choices in the web settings. Are these tasks failing only on my systems, or do other crunchers experience the same problem ? | |
| ID: 60914 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
this morning, 2 of my Windows10 machines received ATMbeta tasks, and all of them failed after around 51 seconds (RTX3070) and around 81 seconds ((Quadro P5000). what kind of junk is this now? even after I set the ATMbeta to "no", they still come in and fail :-(((( So something seems to be wrong with the GPUGRID web settings :-((( | |
| ID: 60915 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
I got 6 ATMbeta so far today. All of them error out with | |
| ID: 60916 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
Same here with this: | |
| ID: 60917 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Erich56, Regarding your preferences, did you answer yes to these questions: thanky you, Bedrich, for your hints. Indeed, I deselected "ATMbeta", but I forgot to deselect "Run test applications". So now I corrected this. Still though, I would guess once "ATMbeta" is deselected, no ATMbeta should be downloaded, regardless whether "run test applications" is selected or not. What happened is rather unlogical :-( | |
| ID: 60918 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
11 WUs on 3 different computers (1 Win11, 2 Linux) with 3 different GPUs failed today. | |
| ID: 60919 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
11 WUs on 3 different computers (1 Win11, 2 Linux) with 3 different GPUs failed today. from what I remember reading somewhere here recently, there was some issue with an expired license which they tried to fix but it failed. This though was true for the Linux version. So, as it looks, the same problem might be true for Windows as well :-( However, I am wondering that no one from the team notices that all the tasks which they send out are failing, and so they would stop the distribution. P.S. I just notice that one of my PCs received serval ACEMD 3 tasks within the past hour - and they also failed after about a minute. See here: http://www.gpugrid.net/result.php?resultid=33725238 Until this morning, they could be crunched successfully. So there seems to exist a major problem wiht GPUGRID at this time :-( | |
| ID: 60920 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
11 WUs on 3 different computers (1 Win11, 2 Linux) with 3 different GPUs failed today. You’re confusing two different apps. acemd3 had the expired license issue, which they tried to fix, but ended up replacing the Linux version with the windows version which remains broken (because a windows app can’t run on Linux) This thread is about the ATM app. Which is not subject to the same licensing issues. ____________ | |
| ID: 60921 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
From January 5th onwards, my Linux hosts have received a limited quantity of new ATMbeta tasks. Application: ATMbeta: Free energy calculations of protein-ligand binding 1.09 (cuda1121) ---------------------------------------------------------------------- Application: ATMbeta: Free energy calculations of protein-ligand binding 1.09 (cuda1121) This is an interesting issue correction comparing to precedent ATMbeta tasks! On the other hand, values for "CPU time since checkpoint:" make me think that "no checkpointing" issue is still pending to correct. This compels for the tasks to be executed with no interruptions from the beginning to the end... Also, They seem to continue failing on Windows hosts. | |
| ID: 60933 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
They fixed the percentage completion issue. | |
| ID: 60934 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
I did the suspend and restart experiment. The unit didn't error out, but it didn't save work done before the suspension. It started at zero and is crunching normally. Let's see if it finishes successfully. Give it a few hours. It looks like we are making progress. | |
| ID: 60937 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Your stop-started task looks to have finished normally for credit. | |
| ID: 60940 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
They seem to continue failing on Windows hosts. which is really too bad :-( | |
| ID: 60944 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
They seem to continue failing on Windows hosts. I now downloaded an ATM on one of my Windows hosts - still failing. To make sure that the problem is not with my system, I double-checked the tasks lists of other volunteers - same thing there. So it seems clear that the license for the Linux app was updated, but NOT for the Windows app. | |
| ID: 60947 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Looking at some of the english-language attempts at that task, they all have Error occurred while processing: C:\DC\BOINC. I don't see any evidence of an expired licence, but there's clearly something else wrong with the re-deployment. | |
| ID: 60948 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
They seem to continue failing on Windows hosts. The license update was for the ACEMD3 app, not ATM. Whatever problem ATM might be having on Windows, it’s not the same issue that they fixed for Linux on ACEMD3. ____________ | |
| ID: 60949 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I don't see any evidence of an expired licence, but there's clearly something else wrong with the re-deployment. ... The license update was for the ACEMD3 app, not ATM. Whatever problem ATM might be having on Windows, it’s not the same issue that they fixed for Linux on ACEMD3. okay, folks, thanks for the information. So all we Windows people can do is: wait and see :-( | |
| ID: 60950 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
They seem to continue failing on Windows hosts. Also, the intended research for ATM tasks can be altered in some way due to this issue. As an example: One of my Linux hosts, #557889, happened to catch early this morning the ATMbeta task TYK2_m15_m16_3-QUICO_ATM_opc-2-5-RND9826_6 This task is the third link of a certain 5 tasks chain, and it is hanging from WU #27642885 This task, by chance, was previously sent to 6 Windows hosts and failed after a few seconds. If it had been sent to two more Windows hosts and (consequently) failed, it would have reached its maximum number of allowed failures, and this particular investigation line would have been truncated. Coincidences happen... | |
| ID: 60951 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I have a _7 task running on a Linux box. That's the last chance saloon - I'll try to look after it. | |
| ID: 60952 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
tar.ext instead of tar.exe | |
| ID: 60953 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I noticed the typo also. Should be easy to fix. Proofreading . . . anyone?? | |
| ID: 60954 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
exact meme probleme. | |
| ID: 60955 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
16:49:42 (4080): wrapper: running C:/Windows/system32/cmd.exe (/c call run.bat) | |
| ID: 60956 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
Thank you for spotting the typo. It has been updated. Hopefully the next round of jobs succeed on windows! | |
| ID: 60957 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Thanks for the update Steve. | |
| ID: 60958 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
I a new researcher/software engineer in the lab. Part of my responsibility is looking after GPUGRID and deploying this updated Quantum Chemistry app. I will try and keep an eye on these forums so issues can be addressed! | |
| ID: 60959 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
I will try and keep an eye on these forums so issues can be addressed! Brilliant, Steve. That would already be a great progress. Thank you! | |
| ID: 60960 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I will try and keep an eye on these forums so issues can be addressed! + 1 | |
| ID: 60961 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
I a new researcher/software engineer in the lab. Part of my responsibility is looking after GPUGRID and deploying this updated Quantum Chemistry app. I will try and keep an eye on these forums so issues can be addressed! +100 | |
| ID: 60962 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Steve wrote on Jan. 10th: Thank you for spotting the typo. It has been updated. Hopefully the next round of jobs succeed on windows! unfortunately, also the new round of jobs does not work on Windows. One after the other fails short time after start :-( See here: http://www.gpugrid.net/results.php?userid=125700 | |
| ID: 61047 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
You seem to have something wrong with your BOINC client. it's impossible to say what, but your stderr output is just blank, which is not normal or an artifact of these tasks. since this is the same system that you saw weirdness with Asteroids also, i do think you have some kind of problem with BOINC itself. it's impossible for us to guess without access to your system though. 09:54:40 (15568): wrapper (7.9.26016): starting so yes, there is still a problem on Windows (probably something wrong in the run.bat file, or a file missing from the environment package or input files. but you have a larger problem as well. while troubleshooting your asteroids problem, I had recommended to upgrade your BOINC client, and I think you did that, but you may have performed an in-place upgrade rather than a fresh install. I would recommend removing all aspects of BOINC on this system. completely delete everything. and re-install from a fresh install package. do not keep anything from the previous install. ____________ | |
| ID: 61048 | Rating: 0 | rate:
| |
|
wujj123456 Send message Joined: 9 Jun 10 Posts: 16 Credit: 2,079,582,323 RAC: 197,495 Level Scientific publications | |
|
Not sure if he has the same problem, but for me, the past few jobs on Windows are sent to the wrong platform AFAIC. | |
| ID: 61049 | Rating: 0 | rate:
| |
|
Geoff Send message Joined: 30 Aug 10 Posts: 2 Credit: 395,788,094 RAC: 126,239 Level Scientific publications | |
|
Windows task failer again, this is a copy of the run file up to the point it hit the error | |
| ID: 61051 | Rating: 0 | rate:
| |
|
Geoff Send message Joined: 30 Aug 10 Posts: 2 Credit: 395,788,094 RAC: 126,239 Level Scientific publications | |
|
Just to add, I've now had multiple failers over the last 10 minutes, all of them are failing at the same point. | |
| ID: 61052 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Ian&Steve C. wrote yesterday: You seem to have something wrong with your BOINC client. it's impossible to say what, but your stderr output is just blank, which is not normal or an artifact of these tasks. since this is the same system that you saw weirdness with Asteroids also, i do think you have some kind of problem with BOINC itself. it's impossible for us to guess without access to your system though. yes, you are right, there is obviously something wrong with this BOINC installation. I will remove it and install it from scratch, once the currently running Climateprediction tasks (which use to last up 14 days or even longer) are through. Nevertheless, it's sad to learn that the Windows version of the ATM app is still faulty. What I don't understand is: do they not test it before hundreds or thousands faulty tasks are being sent out? In fact, a testrun in their own lab would have shown within 5 minutes that still something is wrong. I think these 5 minutes would be worth the time, right? | |
| ID: 61053 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
fully agree | |
| ID: 61055 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
Steve, the researcher, in his first few posts about these tasks said that they don't have any Windows machines in the lab. They only have Linux. I'll post to Gianni that he needs to help get the Windows apps sorted out. | |
| ID: 61056 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
Been 10 months since this was posted. Where is the "hoped for" windows version? Why are you wasting the potential of all of our Windows machines and new fast GPU's? | |
| ID: 61058 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
The'Energy is NaN' error is still around: | |
| ID: 61059 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Hey Keith, If you contact Gianni, pass on the following info I found from my testing. There are 2 issues on the same line in this piece of code in run.bat: @echo Install AToM tar.exe xvf atom.tar python.exe -m pip install ./Acellera-AToM-OpenMM-* || exit 13 python.exe -m pip list 1. The path separator '/' is wrong for Windows, should be '\' instead. This makes pip install choke. This should be a trivial fix. 2. Windows CMD shell scripts do not support inline expansion of the '*' wildcard. So pip install doesn't find the module in the location it expects, being "Acellera-AToM-OpenMM-*" There are a few ways to fix this: - Use the full name of the package folder 'Acellera-AToM-OpenMM-2dd310b8027c68262906a8946f807896b49947b6' This also implies that if this '2dd310b8027c68262906a8946f807896b49947b6' is variable, run.bat should be changed every time - Generate a new atom.tar with a fixed folder name, for example always using 'Acellera-AToM-OpenMM' as the folder name of the package inside atom.tar - and adapting the run.bat pathname to .\Acellera-AToM-OpenMM accordingly - use some scripting magic to pre-expand the wildcard into a variable (e.g. ATOM) and passing that variable to pip install. Something like this could work, but may have mixed results on different Windows installs - so solution 1 or 2 preferred. @echo Install AToM tar.exe xvf atom.tar set PARM1=.\Acellera-AToM-OpenMM-* for %%A in (%PARM1%) do set ATOM=%%A python.exe -m pip install %ATOM% || exit 13 python.exe -m pip list | |
| ID: 61060 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I posted to Gianni and he replied that he copied my message to Steve. | |
| ID: 61063 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
Heres the top half of my dump: | |
| ID: 61064 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
The python package is the large 1.9GB package that downloads to every host at first running of the ATMBeta tasks. It is static and sets up the python environment in the project folder. | |
| ID: 61065 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
Thank you all for the windows debugging info. I am looking into this! | |
| ID: 61069 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Thank you all for the windows debugging info. I am looking into this! thank you Steve, I'm looking forward to crunching ATMs with my altogether 6 GPUs on Windows | |
| ID: 61073 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Thank you all for the windows debugging info. I am looking into this! Thanks for working on this, Steve! I just got a WU called "T0_1-STEVE_TEST_ATM-1-5-RND5320" where I noticed you went for a pre-untarred folder "Acellera-AToM-OpenMM-gitrepo" inside the input file. I'm happy to report that this went past the pip install statement without a hitch and is now happily simulating! Good job! | |
| ID: 61074 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
And done successfully! | |
| ID: 61075 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
Great thanks for the help! The new changes have been passed onto the researchers. Next round of jobs should have the fix. | |
| ID: 61076 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
Just to explain a bit about how this app currently works. | |
| ID: 61078 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
| |
| ID: 61079 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
|
What does this mean: <message> | |
| ID: 61104 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
What does this mean: <message> Googling shows this: "The operation system cannot run %1" is shown when some apps try to open links Sounds like the app is trying to open links that are invalid or badly formed. Or a variation of this: ImportError: DLL load failed: The operating system cannot run %1. | |
| ID: 61106 | Rating: 0 | rate:
| |
|
Greg _BE Send message Joined: 30 Jun 14 Posts: 127 Credit: 110,756,939 RAC: 4,306 Level Scientific publications | |
What does this mean: <message> Lovely | |
| ID: 61107 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Got four failures for ATMbeta resends today, on two slightly differing versions of Linux Mint. All had + python -m pip install ./Acellera-AToM-OpenMM-2dd310b8027c68262906a8946f807896b49947b6 ./Acellera-AToM-OpenMM-gitrepo | |
| ID: 61110 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Got four failures for ATMbeta resends today, on two slightly differing versions of Linux Mint. All had same. i had about 150 of these errors. ____________ | |
| ID: 61111 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
same. i had about 150 of these errors. All of mine have gone to full workunit failure, with too many errors. Some of them have been tried by Windows computers, and have failed there too. | |
| ID: 61112 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Great thanks for the help! The new changes have been passed onto the researchers. Next round of jobs should have the fix. Hi Steve, I notice a new batch of ATMs released, but the fix has only been partially incorporated, leading to failures both on Windows and Linux. The WU's do contain the pre-untarred 'Acellera-AToM-OpenMM-gitrepo' directory which is good, but the 'atom.tar' file is also still included which is both inefficient use of network bandwith as well as leading to errors. Worse is, the run.bat and run.sh files both still have the following statement: python.exe -m pip install ./Acellera-AToM-OpenMM-* On Windows, this still leads to the same old error because of the invalid path separator / instead of \ and because the '*' is interpreted literally instead of as a wildcard. See Task error example here: https://www.gpugrid.net/result.php?resultid=33760402 On Linux, the same task leads to an error because it does interpret '*' as a wildcard, finding 2 AToM folders (from atom.tar and from Acellera-AToM-OpenMM-gitrepo) instead of 1, with a conflicting dependency error as result. See Task error example here: https://www.gpugrid.net/result.php?resultid=33760795 Resolution: Replace the statement python.exe -m pip install ./Acellera-AToM-OpenMM-* by the following in run.bat (Windows): python.exe -m pip install .\Acellera-AToM-OpenMM-gitrepo by the following in run.sh (Linux): python.exe -m pip install ./Acellera-AToM-OpenMM-gitrepo As an optimization: EITHER remove atom.tar from the WU, as well as the corresponding 'tar' statements in run.bat and run.sh OR package Acellera-AToM-OpenMM-gitrepo folder inside of atom.tar instead of Acellera-AToM-OpenMM-2dd310b8027c68262906a8946f807896b49947b6 | |
| ID: 61113 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
same. i had about 150 of these errors. See the reason for both Linux and Windows errors in my post above... | |
| ID: 61114 | Rating: 0 | rate:
| |
|
Steve Volunteer moderator Project administrator Project developer Project tester Volunteer developer Volunteer tester Project scientist Send message Joined: 21 Dec 23 Posts: 34 Credit: 0 RAC: 0 Level Scientific publications | |
|
thank you for the catch again, I will check the correct scripts are being used | |
| ID: 61115 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Task TYK2_m10_m15_2_TEST-QUICO_ATM_500K_dih14fit-0-5-RND5394_0 (ATMbeta) received and is running correctly under Linux Mint 21.3 | |
| ID: 61116 | Rating: 0 | rate:
| |
|
Hans Sveen Send message Joined: 29 Oct 08 Posts: 3 Credit: 402,605,899 RAC: 0 Level Scientific publications | |
|
Hi! | |
| ID: 61125 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Hi! here, too :-) Also the progress bar in the BOINC manager now works fine ! | |
| ID: 61142 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
Has the ATM experiment been stopped? Or can we expect more work in future? | |
| ID: 61211 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
A new batch of ATMbeta tasks is on the field since yesterday. . Where "N" corresponds to the Device Number (GPU) where the task was run on. With ATMbeta tasks I'm not currently experiencing reliability problems, but identifying every single GPU can be useful, for example, to characterize its performance. | |
| ID: 61294 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
A new batch of ATMbeta tasks is on the field since yesterday. Does anyone else have problems loading ATMbeta even though they were explicitly selected in the GPUGrid settings? | |
| ID: 61301 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
No, none at all. | |
| ID: 61302 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
No, none at all. this. you need beta/test tasks selected. ____________ | |
| ID: 61303 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
you need beta/test tasks selected. Silly me. I actually missed that. Thank you. | |
| ID: 61304 | Rating: 0 | rate:
| |
|
Got an error when pause and restart in my non-English system. ×ÓĿ¼»òÎļþ F:\apps\BOINC\data\slots\1\tmp ÒѾ­´æÔÚ¡£ This may mean "A subdirectory or file F:\apps\BOINC\data\slots\1\tmp already exists."or so. Warning: importing 'simtk.openmm' is deprecated. Import 'openmm' instead. ImportError: DLL load failed while importing _openmm: ÕÒ²»µ½Ö¸¶¨µÄÄ£¿é¡£ I can't read this. Is it because of my system lenguage? Or just something wrong with "importing _openmm" or so? | |
| ID: 61337 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Just Windows thing. Doesn't have the character library or something. | |
| ID: 61338 | Rating: 0 | rate:
| |
|
Half-day task without pause may not suitable for me... | |
| ID: 61340 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Tasks are always copied into and crunched in a slot in BOINC. | |
| ID: 61344 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
yup. the only slight difference with GPUGRID ATM (and QChem) is that the environment package is very large (2-3GB when extracted). you do need to provision for that in this case. you don't notice it nearly as much with other projects shipping tiny binaries. | |
| ID: 61345 | Rating: 0 | rate:
| |
|
kotenok2000 Send message Joined: 18 Jul 13 Posts: 78 Credit: 16,175,793 RAC: 9,787 Level Scientific publications | |
|
Boinc server doesn't have correct character library. | |
| ID: 61346 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Heads up: A new batch of ATM (not Beta) was released this morning - just 200 tasks, all allocated now, but it might be a sign of things to come. | |
| ID: 61350 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
Two things to note: Thank you for your notes. Maybe a third thing to point: I've noticed that recently the delay for GPUGRID server to attend task requests has been decreased to 11 seconds, instead of previous 31 seconds. | GPUGRID | update requested by user This affects to every apps, not only ATM. And for small batches, it can cause that tasks ready to send decrease triple the rapid until they run out. | |
| ID: 61354 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
bonjour y a t il des taches quantum chemistry pour windows? | |
| ID: 61355 | Rating: 0 | rate:
| |
|
[VENETO]Fabrizio74 Send message Joined: 30 Apr 16 Posts: 1 Credit: 1,002,610,580 RAC: 865,531 Level Scientific publications | |
|
Good morning, is it possible to process processes lasting 7, 10 hours with RTX 3xxx series cards or possibly resume from the point of view that was stopped without making an error? | |
| ID: 61356 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
Good morning, is it possible to process processes lasting 7, 10 hours with RTX 3xxx series cards or possibly resume from the point of view that was stopped without making an error? Process tasks in less than 7 hours with RTX 3000 cards? YES Stop running tasks and resume them without error or losing progress? NO | |
| ID: 61357 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
bonjour y a t il des taches quantum chemistry pour windows? not yet. ____________ | |
| ID: 61358 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
Gonna go out on a limb here and say a very high percentage of the computers that look for work units from you are Windows based. Why on earth would you design something for Linux first? | |
| ID: 61359 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
Because that’s what they know and use in their lab. They develop on Linux, test, tweak, then port to Windows later. | |
| ID: 61361 | Rating: 0 | rate:
| |
|
Boca Raton Community HS Send message Joined: 27 Aug 21 Posts: 36 Credit: 3,441,856,809 RAC: 24,170 Level Scientific publications | |
Gonna go out on a limb here and say a very high percentage of the computers that look for work units from you are Windows based. Why on earth would you design something for Linux first? Very, very little in the world of computational science starts in Windows. You should see the world of genomics! Basically nothing can be accomplished in Windows. | |
| ID: 61362 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
The non-beta ATMs are flowing again. Hopefully I can get up to 11 completions so the server will start to recognise the true processing speed this time. | |
| ID: 61365 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Waiting to see if the runtime progress bug has been finally eliminated for this app. I know this was fixed on ATMbeta, did it not translate to ATM on the previous batch? ____________ | |
| ID: 61366 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
They were all 0-7 too - and progress during that first segment was always OK. I've not seen a 1-7 or later yet. | |
| ID: 61367 | Rating: 0 | rate:
| |
|
Boca Raton Community HS Send message Joined: 27 Aug 21 Posts: 36 Credit: 3,441,856,809 RAC: 24,170 Level Scientific publications | |
I can say that running 4x on the 4090 has pushed the GPU harder than any other work in the context of power utilization but are running really smoothly. I won't probably run 4x for too long though- pulls almost 400w(!) (never goes above 58c though). My time estimations look like they are working on the systems I have checked today. Edit: Time estimation is not accurate on all of our systems (yet). | |
| ID: 61368 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
|
"No tasks available for ATM", says BOINC | |
| ID: 61369 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
"No tasks available for ATM", says BOINC Same problem here. Edit: My linux machines can get the ATM tasks. But my windows machines cannot. | |
| ID: 61371 | Rating: 0 | rate:
| |
|
zombie67 [MM] Send message Joined: 16 Jul 07 Posts: 207 Credit: 2,149,136,456 RAC: 8,642,407 Level Scientific publications | |
|
Update: My win machines finally got some of the ATM tasks. Not sure what changed, but happy to see it. | |
| ID: 61372 | Rating: 0 | rate:
| |
|
I noticed that the ATM tasks are receiving 1,125,000.00 credits each. This seems several hundred times greater than what I would expect for the computation time of these tasks. | |
| ID: 61377 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
I noticed that the ATM tasks are receiving 1,125,000.00 credits each. This seems several hundred times greater than what I would expect for the computation time of these tasks. That's because BOINC credits are calculated based on computation operations (flops) not computation time, and GPUs have much higher flops than CPUs. | |
| ID: 61378 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
That's because BOINC credits are calculated based on computation operations (flops) not computation time, and GPUs have much higher flops than CPUs. At this project, they aren't calculated at all - they are given at a fixed rate for each application type, set by the adnins. | |
| ID: 61379 | Rating: 0 | rate:
| |
That's because BOINC credits are calculated based on computation operations (flops) not computation time, and GPUs have much higher flops than CPUs. Yes, I well am aware of how BOINC credits were originally designed. That is why I am pointing out the credit issue. If I continued crunching these tasks, the credit would eclipse projects I have been crunching (with GPUs) for 12 years in a matter of days. These even seem high compared to other GPUGRID subprojects. | |
| ID: 61380 | Rating: 0 | rate:
| |
|
roundup Send message Joined: 11 May 10 Posts: 60 Credit: 2,887,555,193 RAC: 38,554,562 Level Scientific publications | |
|
I had 35 ATM Work Units over the recent days and not a single error on 2 Linux machines. | |
| ID: 61395 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I had 35 ATM Work Units over the recent days and not a single error on 2 Linux machines. I too had quite a number of ATMs on my Windows machines, and almost all of them worked well - so obviusly the inital problems with Windows were fixed, which is great! Hence, also my congrats to the developers :-) | |
| ID: 61396 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
On March 4, Richard Haselgrove wrote: The non-beta ATMs are flowing again. Hopefully I can get up to 11 completions so the server will start to recognise the true processing speed this time. On some of my hosts I've processed clearly more than 11 completions, and still BOINC shows up to 20 days in column "remaining time"; which means that no other tasks are being downloaded (and parked in waiting position) as long as 1 task in being processed. Interesstingly enough: on the first or even second day, the behaviour was different: a remaining time of about 8-10 hours was shown, hence more than one task per GPU could be downloaded. And then, all of a sudden, the remaining times changed to up to 20 days - no idea why ??? | |
| ID: 61397 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Usually it means you did other work like the QC tasks which reset the DCF to a higher value. | |
| ID: 61398 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Usually it means you did other work like the QC tasks which reset the DCF to a higher value. For me, on my Linux boot, it's the other way round. I need to set DCF to 0.01 in order to get reasonable estimates for QC tasks (still almost 10x the real duration though), but once ATM gets in the mix, the DCF skyrockets... Anyway, Erich56 being on Windows, unlikely that QC tasks were the issue. But I'm seeing similar results on Windows. Even though ATM tasks consistently finish faster than any original estimate, at some point they go up to an estimated time of 20+ days. | |
| ID: 61399 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Anyway, Erich56 being on Windows, unlikely that QC tasks were the issue. exactly | |
| ID: 61400 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
I now seem to receive several tasks which fail within 1-2 minutes. | |
| ID: 61408 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
I now seem to receive several tasks which fail within 1-2 minutes. I have the same problem: https://www.gpugrid.net/results.php?hostid=610674&offset=0&show_names=0&state=0&appid=41 | |
| ID: 61409 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Why are all these faulty tasks being sent out all of a sudden? Look in the task report on this website. The first one I tried was blank, but the next said: openmm.OpenMMException: Unknown property 'version' in node 'IntegratorParameters' That suggests an error preparing the batch - a project problem, not yours. | |
| ID: 61410 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Why are all these faulty tasks being sent out all of a sudden? Thank you Richard, I did spot what stderr was showing. So it was clear to me anyway that there seems to be a problem with the batch. I keep receiving all these faulty tasks, so I'd better switch to "no new tasks" | |
| ID: 61411 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Why are all these faulty tasks being sent out all of a sudden? all these faulty tasks are "CDK8_" - I have received about 30 of them this afternoon. Once more I am questioning whether tasks are not being testet before a full batch is released. In case of these CDK8, a test taking no longer than a few minutes would have revealed the problem. | |
| ID: 61413 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
CDK8_s are being issued now. I have three running normally, but they're all on Linux machines. That shouldn't be a problem for an error of this type, so I would expect them to run under Windows too - but approach with caution! | |
| ID: 61414 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
Yeah, but what exactly does that have to do with getting work units processed from computers that are primarily running a Windows OS from what I can see of the folks who are contributing here? | |
| ID: 61415 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
Yeah, but what exactly does that have to do with getting work units processed from computers that are primarily running a Windows OS from what I can see of the folks who are contributing here? this is a prime example: https://github.com/gpugrid/gpugrid/issues/1 I know this thread is about the ATM app specifically. but stuff like this is why a Windows build might not be available. the only app at this project without a Windows version is the Quantum Chemistry GPU app (PYSCFbeta). And they basically can't even build it for Windows because the main codebase they are using for their version of the application is not offered for Windows at all. there's no build recipe for Windows. It's a misconception if you think that the applications here are 100% homegrown and original. They are using a lot of other code and applications pieced together and adapted in a custom way to do their specific work. since a major part of their code that they didn't write or maintain isn't available for Windows kind of forces their hand. it's not that they don't want to support Windows, it's either don't do the work at all, or be stuck with Linux-only but at least get some work done, they chose the latter. to be more on-topic with this thread. ATM tasks DO have a Windows version available. some systems produce errors though for some unknown reason, while others work fine. not getting work at all is a problem with your configuration somehow since other windows systems are getting work just fine. ____________ | |
| ID: 61416 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
I have two windows computers running GPU GRD and I'm lucky to get two ATM work units every couple of days, no matter how often I manually request tasks. | |
| ID: 61417 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Once you've validated 11 ATM tasks, the DCF for that application should come down and the estimated times to completion should come down to something reasonable. | |
| ID: 61418 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
Thanks. I've validated well over 11 ATM tasks. Oh well, it is what it is. I just hate to see all this GPU horsepower I have doing nothing. | |
| ID: 61419 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
Bonjour , | |
| ID: 61420 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
Keith Myers wrote: Once you've validated 11 ATM tasks, the DCF for that application should come down and the estimated times to completion should come down to something reasonable. none of my 4 hosts (with total of 7 GPUs) is showing this behaviour, though. | |
| ID: 61421 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
est ce que gpugrid arretera d'envoyer des unites quantum chemistry sur ma gtx 1650 si elles partent toutes en erreur a cause de la quantité de ram et mettra automatiquement ma gtx 1650 sur ATM qui devrait fonctionner coorectement? | |
| ID: 61422 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
est ce que gpugrid arretera d'envoyer des unites quantum chemistry sur ma gtx 1650 si elles partent toutes en erreur a cause de la quantité de ram et mettra automatiquement ma gtx 1650 sur ATM qui devrait fonctionner coorectement? go into your project preferences and disable running test applications and uncheck the Quantum Chemistry project. ____________ | |
| ID: 61423 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
Yes, use an exclude_gpu statement in your cc_config.xml file. https://boinc.berkeley.edu/wiki/Client_configuration#Application_configuration Something like this in the Options section. <exclude_gpu> <url>http://www.gpugrid.net/</url> <device_num>1</device_num> <type>NVIDIA</type> <app>PYSCFbeta</app> </exclude_gpu> The 1650 should be enumerated as gpu#1 in Boinc in relation to the 4060. But check first in the Event Log which card is #0 and #1 in Boinc's thinking. | |
| ID: 61424 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
merci mais cela ne fonctionne pas avec gpugrid car ce dernier ne gere pas de fichier appconfig.xml. | |
| ID: 61425 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
merci mais cela ne fonctionne pas avec gpugrid car ce dernier ne gere pas de fichier appconfig.xml. you refer to appconfig.xml. However, the addition suggested by Keith needs to be done in the cc_config.xml (located in the main BOINC folder). Further, after making all this in the cc_config.xml, stop and restart the BOINC manager. Only then the changes will work. | |
| ID: 61426 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
You asked for a solution for excluding your 1650 from Quantum Chemistry tasks but still able to run both ATM and QC tasks on your 4060. | |
| ID: 61427 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
merci j'ai bien mis dans cc config.xml et je vais attendre des taches atm pour ma gtx 1650. | |
| ID: 61428 | Rating: 0 | rate:
| |
|
[BAT] Svennemans Send message Joined: 27 May 21 Posts: 50 Credit: 467,467,017 RAC: 3,193,585 Level Scientific publications | |
Thanks. I've validated well over 11 ATM tasks. Oh well, it is what it is. I just hate to see all this GPU horsepower I have doing nothing. You can try to reset your DCF to a low value, which may fix the issue at least temporarily. If you're mixing pyscf & ATM WU's on your machine, this will not work for long but with ATM-only it might have lasting effect. - Stop BOINC client - edit client_state.xml (in your main BOINC folder) - look for the <project> section of gpugrid - look inside this <project> section for <duration_correction_factor> - set the value to 0.01 (lower than that is ignored by BOINC and will be updated to 0.01 after the first WU) <duration_correction_factor>0.010000</duration_correction_factor> - save and close - Start BOINC client | |
| ID: 61429 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
je vous conseille de passer sous linux . | |
| ID: 61430 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
Thanks...all kind of over my head. I've been running boinc stuff since 2003 and have never had to edit something. I'm just an old guy now. | |
| ID: 61431 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
after the ATMs have been running well within the past few weeks, almost all ATMs that my hosts received this afternoon failed after less than a minute with error | |
| ID: 61432 | Rating: 0 | rate:
| |
|
tomaras Send message Joined: 4 Mar 20 Posts: 15 Credit: 722,393,917 RAC: 724,166 Level Scientific publications | |
|
I have two windows computers running the ATM tasks and I have not even received a task to run since 3/22/24 | |
| ID: 61434 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
If you look at the server status page https://www.gpugrid.net/server_status.php | |
| ID: 61435 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
je vous conseille de passer sous Linux . | |
| ID: 61437 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
I have two windows computers running the ATM tasks and I have not even received a task to run since 3/22/24 Some ATM batches have been launched in late April 🎉🙂 | |
| ID: 61476 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
what is this? Seems new: | |
| ID: 61479 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
The work unit generator has an incorrect value for estimated time to complete in the task profile. | |
| ID: 61480 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
The work unit generator has an incorrect value for estimated time to complete in the task profile. same thing here, short time ago: https://www.gpugrid.net/result.php?resultid=35071561 this is a new type of failure? What a waste :-( Could someone back at GPUGRID please take care of this? | |
| ID: 61481 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
One of the GPUGrid devs, Adria for the acemd3/Insilico-binding-assay devs said on their Discord server they would pass on the time limit exceeded error messages to the other devs so that the task generator templates can be updated so they get the proper values for the new tasks. | |
| ID: 61482 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Note that these tasks are ACEMD 3, rather than ATM - and they are indeed from a new version of that application, v2.27 deployed 19 Apr 2024 for Windows. So Erich is right to identify this as a new problem. | |
| ID: 61483 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
Note that these tasks are ACEMD 3, rather than ATM - and they are indeed from a new version of that application, v2.27 deployed 19 Apr 2024 for Windows. So Erich is right to identify this as a new problem. This is indeed a pertinent conversation, but if I may point out, it is listed on the wrong thread, for a reason mentioned above..... | |
| ID: 61484 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Note that these tasks are ACEMD 3, rather than ATM - and they are indeed from a new version of that application, v2.27 deployed 19 Apr 2024 for Windows. So Erich is right to identify this as a new problem. sorry folks, I hadn't even caught that the tasks in question are ACEMD3. So my complaint ended up in the wrong thread :-( Anyway, I now deselected ACEMD 3 for the time being. | |
| ID: 61486 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
I wasn't lucky in snagging any of the new acemd3 tasks and app this last pass, I keep gorging on the QC tasks. | |
| ID: 61487 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Likewise. Linux has a continuous supply of QC, only interrupted by the occasional ATM. And no joy yet on Windows. | |
| ID: 61488 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
I wasn't lucky in snagging any of the new acemd3 tasks and app this last pass, I keep gorging on the QC tasks. I have: https://www.gpugrid.net/results.php?hostid=610674&offset=0&show_names=0&state=0&appid=32 Twice. | |
| ID: 61489 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
I restarted downloading ATMs this morning on three of my hosts. | |
| ID: 61537 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
RAS sur mon pc linux mint avec rtx 4060 t rtx a2000. | |
| ID: 61538 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
I restarted downloading ATMs this morning on three of my hosts. not including tasks still in progress, you have 20 tasks processed, and only 4 errors (that's about 1/5th). of those four, 2 were aborted, not computation error. ____________ | |
| ID: 61539 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
I restarted downloading ATMs this morning on three of my hosts. why did I abort 2 tasks - you can see it: they were running, running, running - for many hours - but no CPU at all. Hence, they also were erronous. | |
| ID: 61540 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
the two you aborted show less than an hour of runtime. | |
| ID: 61541 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
... as can easily be seen from successfully completed tasks, CPU time is close to total runtime. In the case of the tasks which I aborted, I realized by looking at the Windows task manager that there was no CPU usage at all, not at any time, so I aborted them. Also a look at the task list shows that CPU usage was "0". So, in some way these tasks must have been faulty | |
| ID: 61542 | Rating: 0 | rate:
| |
|
Ian&Steve C. Send message Joined: 21 Feb 20 Posts: 1048 Credit: 40,228,383,983 RAC: 547,485 Level Scientific publications | |
|
might be an intermittent problem with your computer. like a driver crash/recovery. since you have some tasks that are running fine. | |
| ID: 61543 | Rating: 0 | rate:
| |
|
EA6LE Send message Joined: 28 Dec 20 Posts: 4 Credit: 7,015,359,761 RAC: 2,327,076 Level Scientific publications | |
|
6/20/2024 6:34:33 PM | GPUGRID | [error] Error reported by file upload server: Server is out of disk space | |
| ID: 61549 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Been seeing this issue now for several hours now. | |
| ID: 61551 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
Some files have uploaded, and some tasks reported, but they've now stopped again with a slightly different set of messages. Compare: 21/06/2024 11:46:33 | GPUGRID | [error] Error reported by file upload server: can't write file /home/ps3grid/projects/PS3GRID/upload/2a/BACE_m26_m17_5-QUICO_ATM_GAFF2_RESP-4-7-RND2126_0_1: No space left on server 21/06/2024 11:46:34 | GPUGRID | [error] Error reported by file upload server: Server is out of disk space I interpret the long version as meaning there's no space left on the backing store either, but that's a guess. | |
| ID: 61552 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
And now they've all gone. The quota system is even allowing me to download new tasks again. | |
| ID: 61553 | Rating: 0 | rate:
| |
|
Keith Myers Send message Joined: 13 Dec 17 Posts: 1313 Credit: 6,014,117,459 RAC: 9,864,759 Level Scientific publications | |
|
Uploads are stalled out again. | |
| ID: 61555 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
Uploads are stalled out again. this time, obviously not "disk full", but "transient upload error" | |
| ID: 61556 | Rating: 0 | rate:
| |
|
Bedrich Hajek Send message Joined: 28 Mar 09 Posts: 477 Credit: 9,334,022,716 RAC: 10,781,574 Level Scientific publications | |
|
This is what I am getting in the event log: | |
| ID: 61557 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
now I get the same: | |
| ID: 61558 | Rating: 0 | rate:
| |
|
[PUGLIA] kidkidkid3 Send message Joined: 23 Feb 11 Posts: 94 Credit: 1,004,605,544 RAC: 187,550 Level Scientific publications | |
|
Hi, same here ... disk out of space ... | |
| ID: 61559 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
|
I've seen this before, at another project that produces very large upload files. | |
| ID: 61560 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
|
the problem is back again since late afternoon :-( | |
| ID: 61561 | Rating: 0 | rate:
| |
|
Erich56 Send message Joined: 1 Jan 15 Posts: 1105 Credit: 7,822,620,176 RAC: 1,815,365 Level Scientific publications | |
the problem is back again since late afternoon :-( the uploads worked some time last night, but now again they don't. What's going on over there? | |
| ID: 61562 | Rating: 0 | rate:
| |
|
[PUGLIA] kidkidkid3 Send message Joined: 23 Feb 11 Posts: 94 Credit: 1,004,605,544 RAC: 187,550 Level Scientific publications | |
|
Same problem disk full ... it's sunday ... I'll see you on monday, i hope | |
| ID: 61563 | Rating: 0 | rate:
| |
|
ServicEnginIC Send message Joined: 24 Sep 10 Posts: 572 Credit: 7,512,847,024 RAC: 10,438,421 Level Scientific publications | |
|
Up to 6 new app versions just out of the oven today, 26 Jun 2024. | |
| ID: 61564 | Rating: 0 | rate:
| |
|
Richard Haselgrove Send message Joined: 11 Jul 09 Posts: 1589 Credit: 6,673,194,351 RAC: 8,970,993 Level Scientific publications | |
Up to 6 new app versions just out of the oven today, 26 Jun 2024. Just noticed that on my latest ATM download - it's v1.16, instead of v1.15 The most obvious change is that my BOINC client has estimated the task at nigh on 3 days, compared with 7 hours for the previous batch. I'm putting that down to the usual quirks of runtime estimation at this project, but I'll keep an eye on it. | |
| ID: 61565 | Rating: 0 | rate:
| |
|
NEO83 Send message Joined: 23 Jul 17 Posts: 2 Credit: 133,276,593 RAC: 5,169,147 Level Scientific publications | |
|
https://www.gpugrid.net/result.php?resultid=35373201 | |
| ID: 61566 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
http://www.gpugrid.net/forum_thread.php?id=5454#61506 | |
| ID: 61567 | Rating: 0 | rate:
| |
|
NEO83 Send message Joined: 23 Jul 17 Posts: 2 Credit: 133,276,593 RAC: 5,169,147 Level Scientific publications | |
|
This wont fix the Problem in my case ... | |
| ID: 61568 | Rating: 0 | rate:
| |
|
Pascal Send message Joined: 15 Jul 20 Posts: 62 Credit: 626,122,434 RAC: 3,525,048 Level Scientific publications | |
|
try by disabling the memory integrity on windows 11 ,after these are the only 2 problems that I had and that prevented boinc from working properly on my pc windows. | |
| ID: 61569 | Rating: 0 | rate:
| |


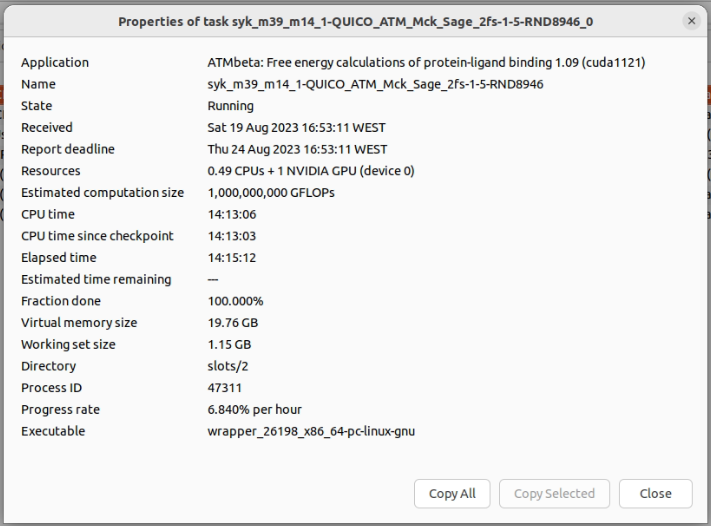{kind=link}
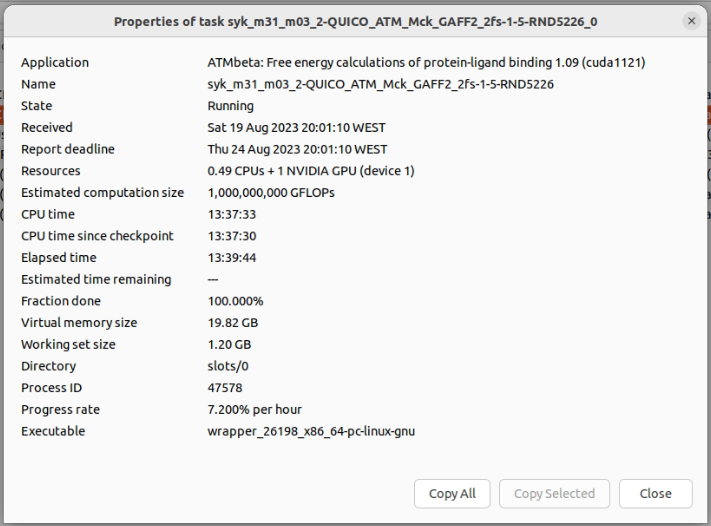{kind=link}
{kind=link}
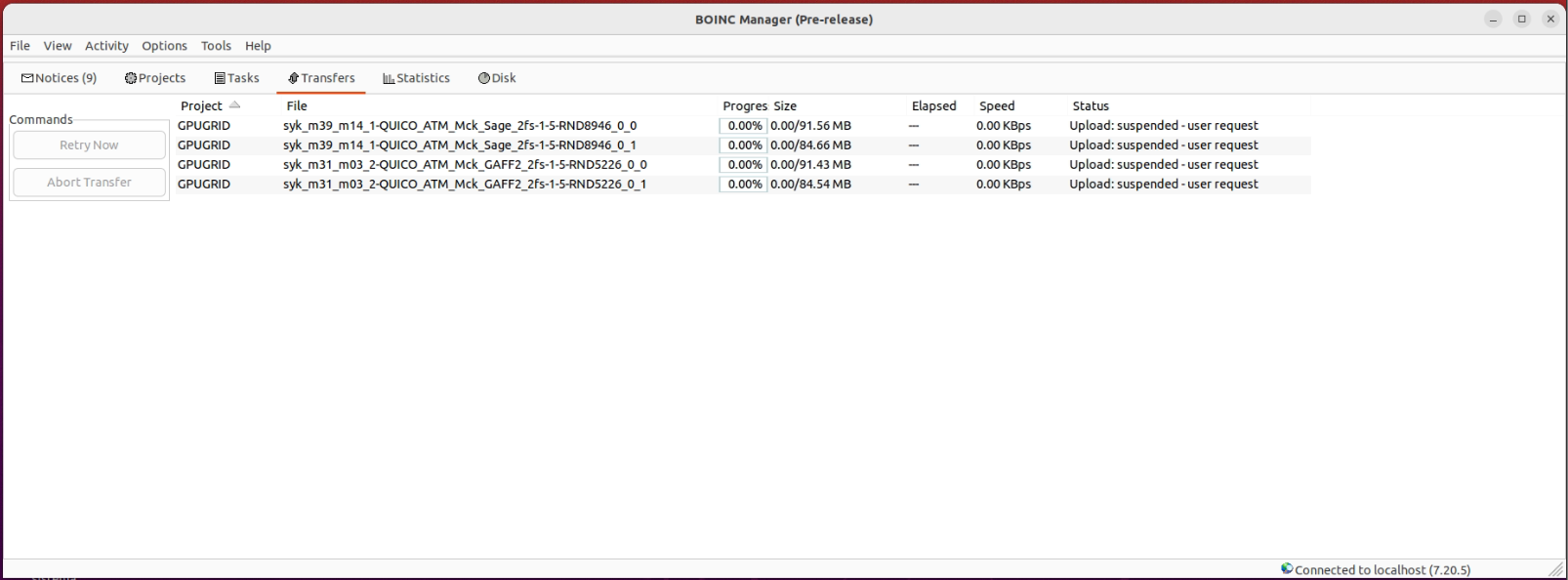{kind=link}
Message boards : News : ATM